The current ChunkStore writes/reads to/from fs directly in a blocking way. This makes it a bottleneck to the vault’s performance when handling large amount of incoming chunks in a short period.
The performance test and benchmark tests shows that the throughput is around 10 MB/s writing speed and 25 MB/s reading speed (0.03s to read an 1MB chunk and 0.083s write an 1MB chunk).
The purpose of this document is to investigate possible alternatives to ChunkStore so that the performance can be improved.
It is assumed that there will be only one vault on one machine.
Database
The main benefits of using a database are:
- DB file can safely be moved from one machine to another (regardless of OS/endianness)
- handles disk IO properly
However, due to the fact that the total_size of chunks to be stored could be huge, such database is not suitable te be executed in in-memory mode (though a benchmark from rusqlite + sqlite3 shows the throughput can achieve 0.022s writes an 1MB chunk).
When executed with db file mode, a benchmark of rusqlite + sqlite3 shows 0.2s writes an 1MB chunk, which is even slower than the current chunk_store.
Key-Value-Store (cask)
A key-value-store can be seen as a simplified version of data_base. Our chunk_store is one of this. However, the current implementation needs to access FS on each operation, makes it behave very similar to the database using a DB file (hence slow).
Another KVS – cask, groups entries into file. This makes it acting like an in-memory database using a page cache (default size is 2GB).
It has two working modes: sync or non-sync. Which toggles whether carries out file.sync_data() on each write operation.
A benchmark shows 0.077s write an 1MB chunk with sync and 0.018s writes an 1MB chunk without sync.
It needs to be noted that:
- When the limit of 2GB reached, a new log_file will be created and used. On request of
getan entry, the log file contains the target will be loaded. This means there is chance max 4GB need to be loaded. - The
mutationof data is achieved byappend entry. i.e. when delete an entry, a specialEntry::Deletewill be appended to the tail of the log_file; when modiy an entry, the new copy will be appended. This makes the real used disk space will be totally different to the statistics. And in the extreme case, unlimited log files will be generated by just repeatedly updating a single entry.
Background Threading ChunkStore
Detached Worker Threads
If the chunk_store is only used for immutable_data (no mutation), the put operation can be put into a detached worker thread.
pros:
- simplest to implement
- super fast regarding the burst throughput
cons:
- can only be used for immutable_data
- when
gethappens at the same withput, may need to ask addiontional copies to be fetched, due to the uncompleted worker thread - in the extreme case, a
getrequest may return with failure if theputworker threads haven’t been completed on the majority of the DMs - mutliple threads accessing FS at the same time may take a longer total time to complete
- when there is burst of chunks, there might be too many threads to be spawned.
Managed Worker Threads
The Joiner of each worker thread of put operation can be stored. And a later on get or mutate operation has to wait till that worker thread completed.
We may want something like HashMap<DataId, Joiner>, and a Joiner for completed thread shall be removed from this map.
pros:
- can be used for immutable_data as well
- super fast regarding the burst throughput of put
cons:
- mutliple threads accessing FS at the same time will take a longer total time to complete
- when there is burst of chunks, there might be too many threads to be spawned.
- performance benchmark is dependent on usage pattern, i.e. get or mutate operation to non-stopped worker thread affects throughput.
The performance test and benchmark tests on the tryout implementation shows that the throughput is around 55 MB/s writing speed and 30 MB/s reading speed (0.03s to read an 1MB chunk and 0.017s write an 1MB chunk). The slow down on reading speed is because the get operation needs to wait for the completion of put operation.
pub struct ChunkStore {
...,
workers: HashMap<Key, (Arc<AtomicBool>, thread::Joiner)>,
keys: BTreeSet<Key>,
}
impl ChunkStore {
fn clean_up_threads(&mut self, key: &Key) {
let _ = self.workers.remove(&key);
let mut completed_threads = Vec::new();
for (key, &(ref atomic_completed, _)) in self.workers.iter() {
if atomic_completed.load(Ordering::Relaxed) {
completed_threads.push(key);
}
}
for key in &completed_threads {
let _ = self.workers.remove(key);
}
}
pub fn put(&mut self, key: &Key, value: &Value) {
self.clean_up_threads(key);
let atomic_completed = Arc::new(AtomicBool::new(false));
let atomic_completed_clone = atomic_completed.clone();
let joiner = thread::named("background_put", move || {
// serialise data and write the file.
atomic_completed_clone.store(true, Ordering::Relaxed);
});
let _ = self.workers.insert(key, (atomic_completed, joiner));
let _ = self.keys.insert(key);
}
pub fn get(&mut self, key: &Key) -> Value {
self.clean_up_threads(key);
// read file from FS
}
pub fn delete(&mut self, key: &Key) {
self.clean_up_threads(key);
self.keys.remove(key);
// delete file from FS
}
pub fn has(&self, key: &Key) -> bool {
self.keys.contains(key)
}
pub fn keys(&self) -> BTreeSet<Key> {
self.keys
}
}
Single thread background chunk_store
Since that will be I/O and not CPU bound, more than one worker threads access the file system at the same time gains nothing in total.
It is suggested to have one single chunk store thread that does the I/O and communicates with the event thread via channels.
pros:
- super fast regarding the burst throughput of put
- single access to the FS
cons:
- the backgroud chunk_store could be very retard and requires a large cache to hold un-processed chunks
- DM needs to
expectthe results from the background chunk_store via channel - many public function of getters (such as
has,keys,used_spaceandmax_space) now need to switch to report via channel - the mutate operations needs to be handled in proper order by the background chunk_store
enum CSOperations {
Put(Key, Value),
Get(Key),
Has(Key),
Delete(Key),
GetKeys,
GetUsedSpace,
GetMaxSpace,
Terminate
}
enum CSResponses {
GetResponse(Value),
Has(bool),
Keys(BTreeSet<Key>),
UsedSpace(u64),
MaxSpace(u64),
}
pub struct ChunkStore {
...,
cs_op_sender: mspc::Sender,
cs_rsp_receiver: mspc::Receiver,
_joiner: Joiner,
}
impl ChunkStore {
pub fn new() -> Self {
let (cs_op_sender, cs_op_receiver) = mpsc::channel::<CSOperations>();
let (cs_rsp_sender, cs_rsp_receiver) = mpsc::channel::<CSResponses>();
ChunkStore {
...,
cs_op_sender: cs_op_sender,
cs_rsp_receiver: cs_rsp_receiver,
_joiner: thread::named("Background chunk_store",
move || {
let worker = Worker::new(cs_op_receiver, cs_rsp_sender);
worker.run();
}),
}
}
pub fn handle_put(&self, key: Key, value: Value) {
self.cs_op_sender(CSOperations::Put(key, value))
}
pub fn handle_get(&self, key: Key) -> Value {
self.cs_op_sender(CSOperations::Get(key));
loop {
if let Ok(CSResponses::GetResponse(value)) = self.cs_rsp_receiver.try_recv() {
return value;
}
}
}
pub fn handle_delete(&self, key: Key) {
self.cs_op_sender(CSOperations::Delete(key))
}
fn has_chunk(&self, key: Key) -> bool {
self.cs_op_sender(CSOperations::Has(key));
loop {
if let Ok(CSResponses::Has(result)) = self.cs_rsp_receiver.try_recv() {
return result;
}
}
}
fn chunk_keys(&self) -> BTreeSet<Key> {
self.cs_op_sender(CSOperations::GetKeys);
loop {
if let Ok(CSResponses::Keys(result)) = self.cs_rsp_receiver.try_recv() {
return result;
}
}
}
fn get_used_space(&self) -> u64 {
self.cs_op_sender(CSOperations::GetUsedSpace);
loop {
if let Ok(CSResponses::UsedSpace(result)) = self.cs_rsp_receiver.try_recv() {
return result;
}
}
}
fn get_max_space(&self) -> u64 {
self.cs_op_sender(CSOperations::GetMaxSpace);
loop {
if let Ok(CSResponses::MaxSpace(result)) = self.cs_rsp_receiver.try_recv() {
return result;
}
}
}
}
pub struct Worker {
...,
cs_rsp_sender: mspc::Sender,
cs_op_receiver: mspc::Receiver,
}
impl Worker {
pub fn new(cs_op_receiver: mspc::Receiver, cs_rsp_sender: mspc::Sender) -> Self {
ChunkStore {
...,
cs_rsp_sender: cs_rsp_sender,
cs_op_receiver: cs_op_receiver,
}
}
pub fn run(&self) {
loop {
while let Ok(operation) = self.cs_op_receiver.try_recv() {
match operation {
Put(key, value) => self.put(key, value),
Get(key) => self.cs_rsp_sender.send(CSResponses::GetResponse(self.get(key))),
Has(key) => self.cs_rsp_sender.send(CSResponses::Has(self.has(key))),
Delete(Key) => self.delete(key),
GetKeys => self.cs_rsp_sender.send(CSResponses::Keys(self.keys())),
GetUsedSpace => self.cs_rsp_sender.send(CSResponses::MaxSpace(self.used_space)),
GetMaxSpace => self.cs_rsp_sender.send(CSResponses::UsedSpace(self.max_space)),
Terminate => return,
}
}
}
}
}
Using a buffer
A buffer can be used as an optimisation to the current chunk_store. Simply by using an lru_cache, the performance of current chunk_store on read access can be improved a lot when a high cache-hit rate is expected.
The approach of single thread background chunk_store can be optimised further by using a buffer and single thread background put inside.
pros:
- super fast regarding the burst throughput of put and get (with high cache-hit rate)
- single background access to the disk
- controllable resource usage (RAM and threading)
cons:
- the buffer needs to be carefully maintained to retain the proper operation sequence
- chunks might not get flushed to disk due to un-expected termination
enum Status {
InMemory,
Flushing,
OnDisk,
}
struct Chunk {
value: Value,
time_stamp: Instant,
status: Status,
}
impl Chunk {
fn new(value: Value) -> Self {
Chunk {
value: value,
time_stamp: Instant::now(),
status: Status::InMemory,
}
}
fn set_flushed(&mut self) {
if self.status == Status::Flushing {
self.status = Status::OnDisk;
}
self.time_stamp = Instant::now();
}
fn set_flushing(&mut self) {
self.status = Status::Flushing;
self.time_stamp = Instant::now();
}
fn get_value(&mut self) -> Value {
self.time_stamp = Instant::now();
self.value
}
fn is_expired(&self) -> bool {
chunk.status == Status::OnDisk && self.time_stamp.elapsed > EXPIRY_DURATION
}
fn can_be_purged(&self) -> Option<Duration> {
if chunk.status == Status::OnDisk {
Some(self.time_stamp.elapsed)
} else {
None
}
}
}
enum CSOperations {
...,
Flushed(Key),
}
pub struct Worker {
...,
cs_op_sender: mspc::Sender,
buffer: BTreeMap<Key, Chunk>,
worker: Option<(Key, thread::Joiner)>,
}
impl Worker {
pub fn run(&self) {
......
Flushed(key) => self.handle_flushed(key),
}
fn handle_flushed(&mut self, key: Key) {
if let Some(chunk) = self.buffer.get_mut(key) {
chunk.set_flushed();
}
if let Some((work_key, _)) = self.worker {
if work_key != key {
return;
}
}
self.worker = None;
self.purge_and_flush();
}
fn purge_and_flush(&mut self) {
// purge chunks that `chunk.status == Status::OnDisk && chunk.is_expired()`
// if still too many, keeps purge `can_be_purged` chunks from oldest till buffer is not too large
if self.worker.is_some() {
return;
}
// pick an oldest InMemory chunk in the buffer
chunk.set_flushing();
let cs_op_sender_clone = self.cs_op_sender;
let joiner = thread::named("background_put", move || {
// serialise data and write the file.
cs_op_sender_clone.send(CSOperations::Flushed(key));
});
self.worker = Some((key, joiner));
}
fn put(&mut self, key: Key, value: Value) {
self.buffer.insert(key, Chunk::new(value));
self.purge_and_flush();
}
fn get(&mut self, key: Key) -> Value {
if Some(chunk) = self.buffer.get_mut(key) {
chunk.get_value()
} else {
// read from disk
}
}
fn delete(&mut self, key: Key) {
if Some(chunk) = self.buffer.remove(key) {
match chunk.status {
OnDisk => // delete from disk,
ImMemory => // do nothing,
Flushing => // wait till join then delete from disk,
}
} else {
// delete from disk
}
}
}
MixedUp
It is possible to having one vault owns multiple chunk_store, which uses different approaches depends on the data type.
For example, for immutable_data, it can use a immutable_chunk_store, which completes put operation in spawned detached worker loader.
For mutable_data, a mutable_chunk_store, which uses in-memory database or background chunk_store.
pros:
- each specific data type has its most suitable approach to achieve the best performance with least bad effects
cons:
- can have many duplicated code and a larger code base to maintain
Avoid serialisation of ImmutableData
The API of current chunk_store takes Value in as serialisable then carries out serialisation before writing it to file. A benchmark test shows that 0.015s serialise an 1MB chunk.
To make comparation fair, the above benchmark tests of rusqlite and cask all include serialisation of data. When get that part removed, the evaluation shows 0.0025s writs an 1MB data for cask without sync and 0.0017 writes an 1MB data for in-memory database.
If the immutable data (normally will be as large as 1MB size) will be the main burden to the chunk_store. It will be worth to consider make value as Data type, and use ImmutableData.value() directly to avoid serialisation.
A quick benchmark test on per-put threading chunk_store without serialising the immutable data shows 0.005s writes an 1MB data.
Using shorter file_name
The current file name for a stored chunk needs to retain the id and version info for a quick query. This results in a much longer file name (72 hex chars for immutable_data and 88 hex chars for mutable_data).
If the id and version info to be stored in a separate cache (in-memory data structrue or a data_base), then a much shorter name, say 8 hex chars, can be used as the file name of chunks.
The current chunk_store::keys() query can then be no longer a cost iteration in file system, but a quick in-memory query.
The map can be Vec<Key>, and file_name can be calculated as file_name = Sha3_224(serialise(key)).to_hex().trucate(16) (which has a collision rate of 1/2^64).
alphanumeric name (non-case-sensitive and skips I,O,U,Z) could be used to push down the collision rate to 1/2^80.
Summary
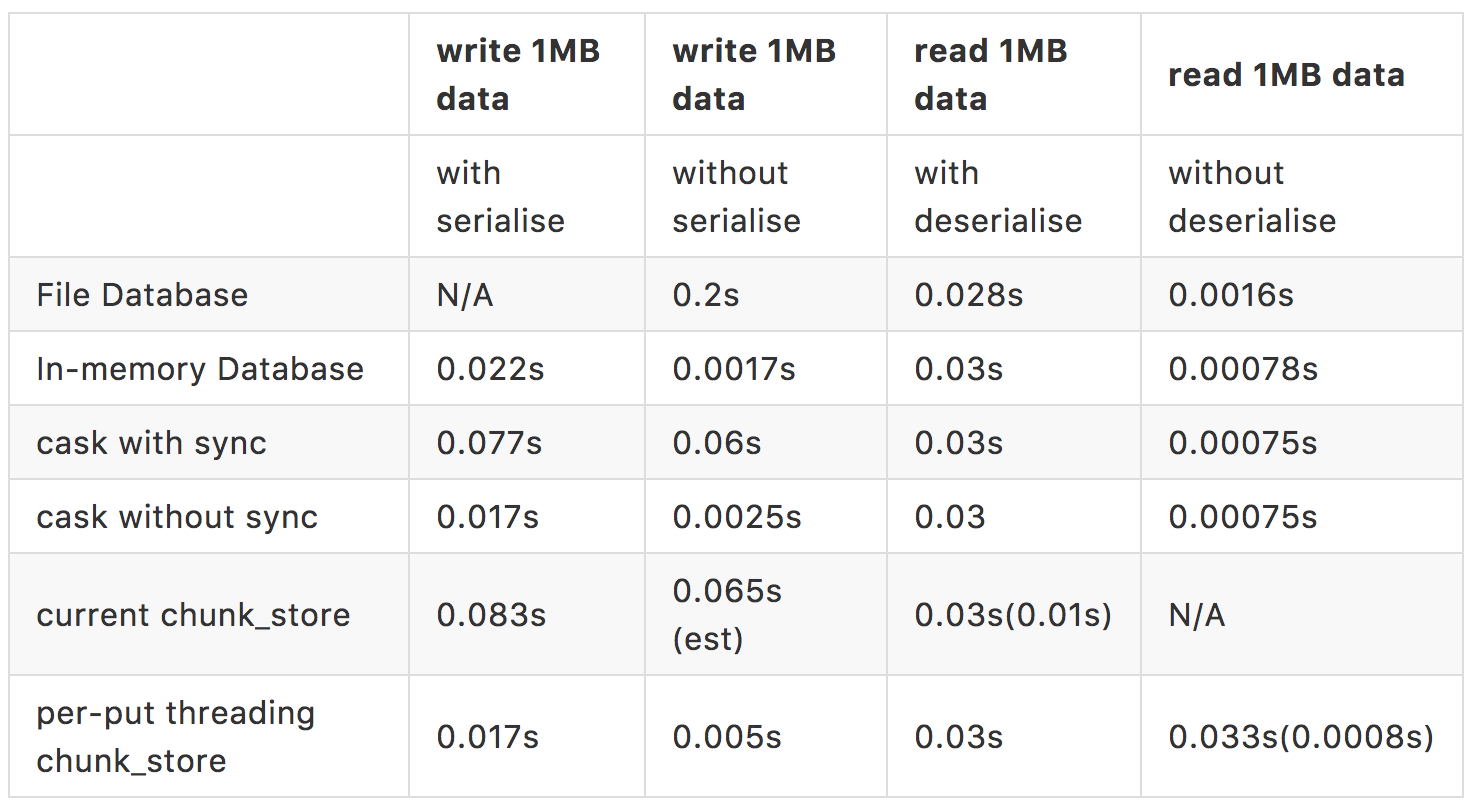
Note:
- When construct an ImmutableData from Vec, a hash of sha256 currently will be executed to calculate the name. This turned out to be a more cost expensive operation than de-serialisation. To compare the performance, a fake operation (return empty Data::Structured) has been used which proves the similiar result (0.0008s) as to the im-memory database or cask without deserialisation. This indicates an ImmutableData constructor from name and value directly might be necessary.
- The tests were exectued with Ubuntun 14.04 64bits. When executed the same benchmark tests on the same machine with Windows 8 64bits using curren chunk_store, the read performance shows an improvement to
0.01s read 1MB data. However the write performance doesn’t have any change.

