I’m building an energy backend application in Node JS that needs high throughput and investigating the best approach. I read that these are the current restrictions for MD:
The MutableData data type imposes the following limits:
Maximum size for a serialised MutableData structure MUST be 1 MiB;
Maximum entries per MutableData MUST be 100;
Not more than 5 simultaneous mutation requests are allowed for different keys;
Only 1 mutation request is allowed for a single key.
At the moment I found out that reading MD in parallel I get about 1 MD per second (with 25 MD’s).
Can I expect big performance increase when I run my own vault in the future? Is there a performance difference between MD/NFS?
NFS doesn’t do anything fancy though, the difference in time will be insignificant as most is spent on the wire anyways. I think most of the emulations will be rather simple abstractions of common models that you’d otherwise code the same way yourself, but are rather slim in their actual performance overhead.
Most, if not all of these, are limits we currently impose explicitly while testing this new feature. We intend to change if not lift most once we have a better understanding of how this behaves in reality and what we can and can’t allow.
This one will stick with us for a while though as it is hard enough to agree on one concurrent change in a distributed system. As it stands right now, a change is bound to the version of the entry and will be rejected if those don’t match - then the client should fetch and try again. This will probably stay this way for a while.
All this said, the MD has the disadvantage of - in its current implementation - centralising a lot of information on the same set of nodes (as the address is with the MD not its keys) and one reason we have those limits is that we are concerned about what that might mean for the overall thread and vulnerability of the network - especially if those keys are predictable, like in the case of the comments-feature.
As we haven’t actually rolled out the feature in the network itself, I assume you are using mocked-routing? This only runs on your local system though, depending on the boundaries of your system, while in reality the bottle neck will most likely be the wire (meaning latency) between the nodes.
As usual the best for high-throughput is caching. Especially if you have single-instance behaviour (meaning only one instance might write to the same MD at the same time), you could cache the result, return and only occasionally write (like once a second for e.g.) like redis does. Another thing would be that you shard the data, and read/write from different MDs then have different client instances, each one having their own safe-lib and connection to the network. This way you’d balance the load across multiple nodes in the network (as other parts are answering for each MD) and on your system. Though whether the later is really more efficient I am not sure, considering the new version uses mostly async already and the wire will still be the bottleneck, not CPU time this particular process has…
What exactly are you intending to build? We’d love to know about more use cases, so we can include them into our models an plans.
I built an energy application that reads the kWh/m3 gas consumption in my house and my solar production from my roof. I also created simulation streams with other energy producers like windmills. The app reads the metering from an external source and stores it in SD/MD on Safenetwork. Every hour the consumer and producer settle a kWh transaction and the SD/MD is updated. I have about 5 streams of data that are stored in SD/MD and archived on NFS when the SD/MD is full.
I was wondering if this is the best way to solve the problem. Performance can be an issue when handling 1000s of SD/MDs for multiple users.
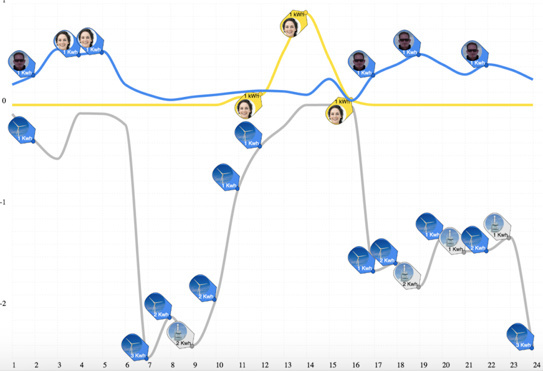
From user perspective it looks like this:
The blue line is my participation in a windmill, the yellow line is my solar panel production and the grey line is my consumption. I can buy energy realtime from other producers based on my preference when I haven’t enough production myself. You see the consumption patern of my energy neutral house in the Netherlands with temperatures around 0, my heatpump uses energy in the morning and evening.
My working concept is build in Node JS that reads a third party API and publish the result in Structured Data, when available I migrate to MD. The front-end is build with AngularJS and Javascript. Performance will be a challenge with these kind of centralized functionalities, but with the right architecture I can solve this issue. In the future I also want to add a coin for the settlement of a kWh for consumer from producer.
I will visit your presentation in Brussel, last time in Amsterdam I couldn’t make it. Would be cool if we can make a tutorial, importing external data to Safenetwork can be a generic design pattern that every developer can use.
edit: my Launcher had some issues, now I can read 25 SD’s in 3 seconds…this looks promising.
The maximum number of allowed entries has been increased from 100 to 1000 since Test 19. I’m not sure whether they’re for protecting the network from spam or abuse, or if they’re functional limits that the network will be optimized for.
Actually I was referring to the file size contained in a MD not how many puts we get on the test nets or Alpha networks. It was nice having that increase though.
The MutableData data type imposes the following limits:
Maximum size for a serialised MutableData structure MUST be 1 MiB;
Maximum entries per MutableData MUST be 100;
Not more than 5 simultaneous mutation requests are allowed for different keys;
So my question is, will the file size limit inside an MD object be lifted. Referring to the 1 MiB limit. Hope this makes sense. Thanks
Will the limits on MD size (1000 entries, and 1MB size) be increased?
If not, will the API be enhanced to make it easier to handle cases where these limits are exceeded (eg by helping chain multiple MD together when more than 1000 entries are needed)?