This weekend I greatly optimized network simulation. For example, for 900000 iterations the duration went from 5h48 to 1mn20.
Here are the optimizations, with new duration of 100000 iterations displayed at each step (initially 2mn52):
-
Reverse fields order in Prefix structure so that entries in btree maps are ordered by bits value instead of len value. This allows to get the section containing a node, by finding the first entry less than its name instead of iterating over all the entries.
=> 2mn48 -
To get the neighbouring sections, make a series of targeted tests instead of testing all possible sections. The algorithm is the following: for each position in prefix:
-
flip corresponding bit from the prefix and test it
-
if test is unsuccessful, shorten the prefix and test again
-
shorten until success or until modified bit is reached
Note: Testing longer prefix is of no use because corresponding section are healthier and so, we don’t want to relocate nodes to them.
=> 2mn44 -
-
Cache sections drop weights. Recompute it only when a section is split or merged and update it when a node is added or removed. Use this cache to compute total network drop weight.
=> 2mn -
Use this cache to compute random node to drop
=> 1mn29 -
captured output at end of simulation instead of every event.
=> 3s
Additionally, I have:
-
corrected the problem that only neighbouring sections were considered to find an unhealthy section. I was forgetting that the distant section itself could be unhealthy too. The result is slightly improved (3000 more nodes on a total of 580000 after 900000 iterations).
-
removed inc_age parameter because I don’t see why age of nodes would be incremented at section merge or split (besides only those in the first half were incremented in case of split).
-
added a parameter to specify if node relocations are local or distant
-
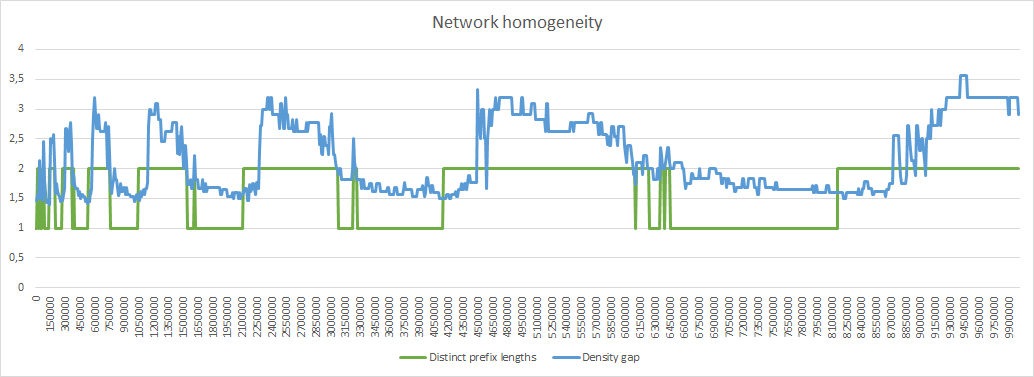
displayed the number of distinct prefix lengths. A homogeneous network should have at most 2 distinct prefix lengths.
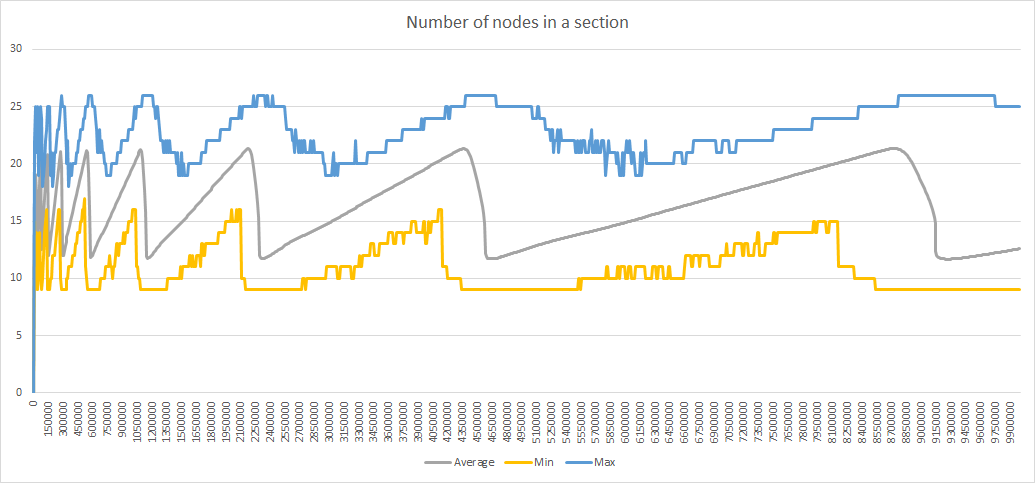
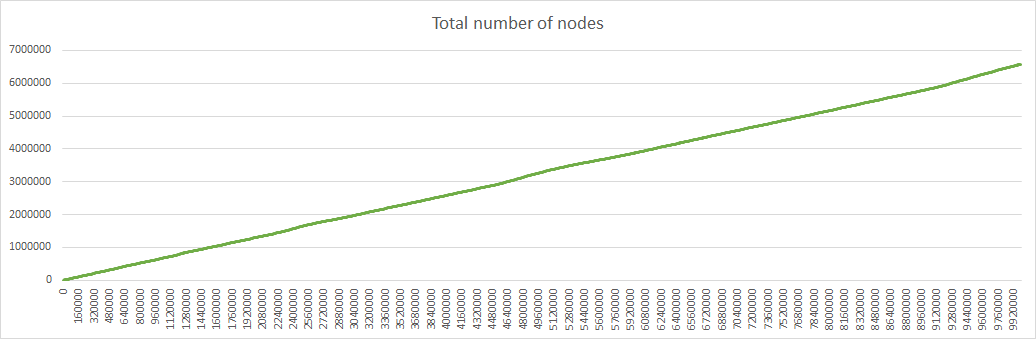
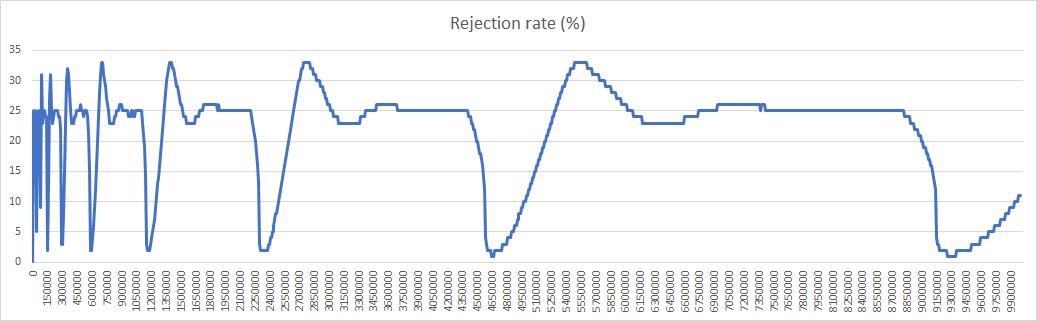
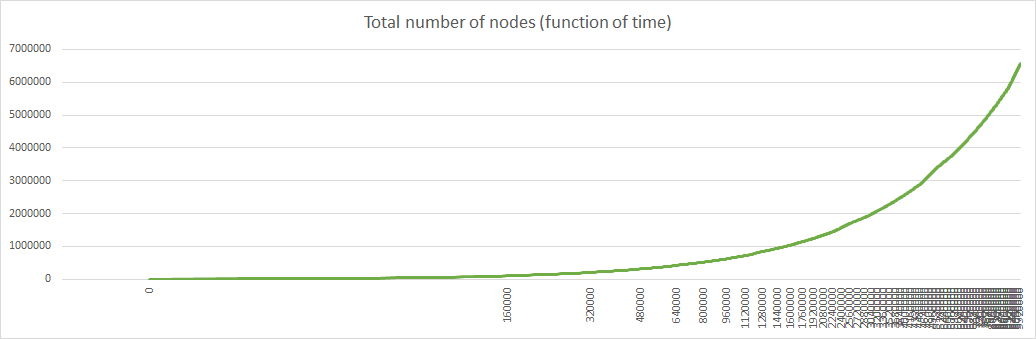
With these optimizations simulations with 10000000 iterations become possible (they take 2h52mn on my PC). Here are the results with max_young=4, init_age=4, relocation_rate=aggressive, relocation_scope=local:
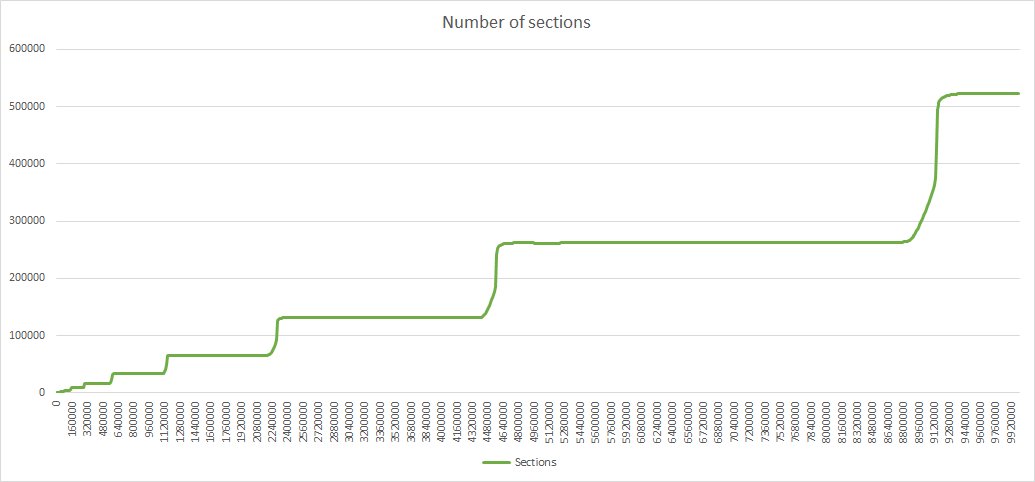

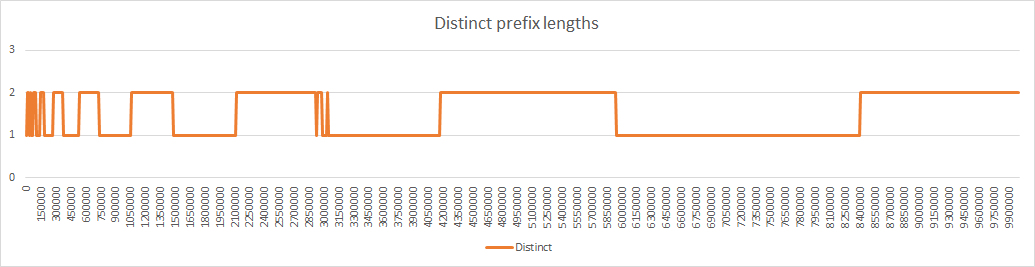
With relocation_scope=distant the results are similar except for the discrepancies indicated last week, with appearance of 3 distinct prefix lengths:

Sections with 3 distinct prefix lengths appear in 129 iteration with sometimes several sections having the shorter prefix, up to 6 sections like at iteration 9670000:
| Prefix len | Count | Average | Min | Max | Standard dev |
|---|---|---|---|---|---|
| 17 | 6 | 16.83 | 14 | 19 | 1.94 |
| 18 | 2560 | 19.01 | 9 | 25 | 4.86 |
| 19 | 519144 | 12.06 | 8 | 16 | 1.16 |
| All | 521710 | 12.09 | 8 | 25 | 1.30 |
I think the explanation is the following: with random relocations applied on thousands of sections it happens that some of them lose a lot of nodes. With local relocations, this will create an excess of nodes in the sections around such a weak section, so there is a high probability that these nodes will come back to their initial section. With distant relocation the nodes are sent far away and the probability that a node is relocated to the neighbourhood is low, or more exactly standard without any consideration that there is a weak section here. When this weak section has less than 8 nodes, it will merge and create a new section with a shorter prefix length, hence the appearance of 3 distinct prefix lengths.
Distant relocations are more secure because they prevent section targeting, but this instability is harmful. So, to try to solve both problem I have added a third value to relocation_scope: mixed value which indicates a 50%/50% probability between local and distant relocation.
Simulation with relocation_scope=mixed shows that the instability has not totally disappeared, but the results are better: there are only 9 iterations with 3 distinct prefix lengths and each time there is only one section with the shorter prefix.
Then I wanted to find the right mix of local and distant relocations. So, I have renamed this parameter and modified it to take a numeric value for the distant relocation probability. I have got the following results with various values for distant relocation probability:
| Distant relocation probability | Iterations with 3 distinct prefix lengths |
|---|---|
| 100% | 129 |
| 70% | 96 |
| 50% | 9 |
| 30% | 29 |
| 0% | 0 |
The result for 30% is disappointing because it means we still get 3 distinct prefix lengths with a low rate of distant relocations, which is both unsecure and unstable.
Then I modified the program, to not relocate a node when relocation would trigger a section merge (meaning its size is GROUP_SIZE before relocation). That was not enough so I changed the condition to size <= GROUP_SIZE + 1 (meaning that I also don’t to want to risk a merge if a node drops the section afterwards). There is still one iteration with 3 distinct prefix lengths at 100% distant relocation probability, but the end is near.
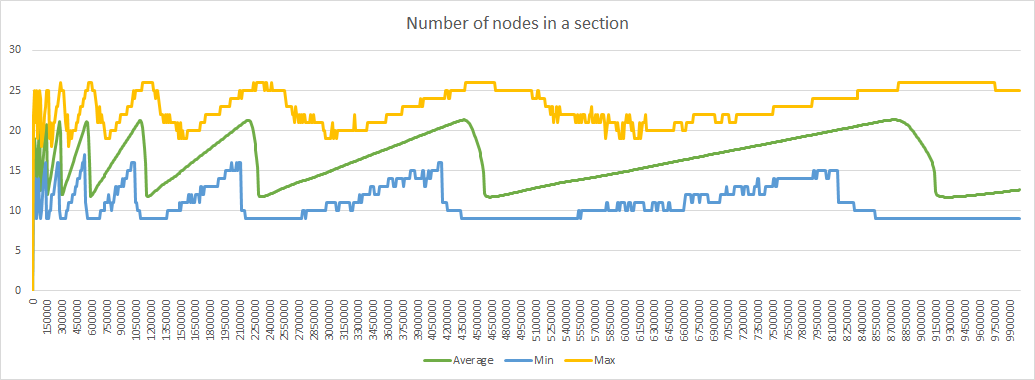
Last try was with the same condition but with 80% distant relocation probability, and at last there are at most 2 distinct prefix lengths all along the simulation. With 80% probability of distant relocation each time a node is relocated, targeting a section remains impossible.
So, finally I have got a network that is both stable and secure.
Another interesting feature of this algorithm is that the minimum number of nodes in a section is higher (9 instead of 8):