Pre-RFC: Data Chains, Part 1
Introduction
In this document we propose to improve the robustness and security of the SAFE network through the addition of a Chain which records section membership changes. For a refresher on sections, see the Disjoint Sections RFC.
A Chain is a network-wide collection of blocks where each block records a section membership change such as the addition of a new node or the merging of two sections. Each section creates and signs new blocks for its portion of the record. The blocks are linked to each other by every block containing a hash of its parent block, thus forming a chain that can be cryptographically verified by any node.
By agreeing on their portion of the chain via consensus, we ensure that all correctly-functioning nodes eventually agree on the nodes in their section. Furthermore, an external observer such as a client or a node from a neighbouring section can use the chain to verify that a section is authentic.
Motivation
Chains as proposed by this document are a substantial step towards the full implementation of Data Chains. Data chains provide cryptographic proof of what data is stored on the network, and who the legitimate members of the network are.
Although this first part does not yet concern data and focuses on the changes of membership and the network’s structure only, this will already have several benefits:
Secure Hop Messaging
Secure Hop Messaging hasn’t been merged yet, mainly because of ambiguities regarding which section lists to sign, and the nodes’ differing views of the “current” state of the network. This chain will help with that, as the following example illustrates:
Section A sends a message via section B to section C:
- The accumulating node in
Ainserts its latest blockA5, and sends the message as soon as it is signed by a quorum of the members ofA5. - Section
Bhasn’t fully exchanged its signatures forA5yet, but the relaying node inBalready has signatures forA4from a quorum of its own blockB8. It inserts those signatures,A4andB8. - The receiving node in
Chas signatures fromC3of the blockB9. It inserts those signatures,B9andC3. - Every other node in
Chas that same blockC3in its chain and will thus agree that the message is valid:
The node knows that C3 is valid. A quorum of C3 signed B9. B9 contains the hash of B8. A quorum of B8 signed A3. A quorum of A4 signed A5. And a quorum of A5 signed the message.
Network verification by reconnecting clients
When a client disconnects from the network and reconnects at a later time, currently it has no guarantees that the network it connected to is indeed the same as the one it had been connected to before. The chain will provide a means of verifying that.
A disconnecting client will be able to save a known part of the chain to the disk. When connecting again, it will receive a current version of the chain. Since all parts of the chain for a single network stem from a single Genesis block, the known part and the current part will have a common ancestor, and there will exist a cryptographically verifiable sequence of proofs for the churn events connecting the last session and the current one via that ancestor. That sequence will prove that the current network is in fact the same one that the client was connected to before.
An optimised verification process is proposed in the “Bootstrapping Trust” section below.
Terminology
- The chain is a record of the network’s history, and the primary concern of this document.
- A block is an element in the chain, describing one change. Blocks as defined here closely resemble link blocks in the Data Chains RFC.
- A chain segment is a linear sequence of blocks within the chain describing part of a single section’s history.
- Each node stores a subset of the chain in its chain cache; these are known blocks.
- Committing a block means adding it to the chain cache, and vice-versa, except that in some uses committing implies the block is for one’s own section, or possibly a neighbour.
- A quorum is a subset of a collection of nodes that is large enough to make a decision in the name of that collection; the exact definition requires further discussion.
- In each section there is a primary node whose task it is to propose the next blocks to be committed. See Consensus Algorithm for details.
Chain Overview
A chain is similar to a blockchain, but differs in several important ways:
- A chain is a Directed Acyclic Graph with a single root node, corresponding to the history of a network.
- Nodes in the network are distributed into multiple sections; each section’s history corresponds to a subset of the chain, and no node needs to know about the entire network or chain.
- Each new block is created by a single section, excepting merges which involve two sections.
- Blocks are self-validating, in that each contains signatures showing approval by a quorum of the previous block’s membership.
- Security is provided by decentralised algorithms that make it difficult to hijack a section.
A visualisation of a subset of a chain containing the recent history from sections 00, 01 and 1 is shown below. Note how section 00 and 01 share common history from before they split out of section 0. The arrows point from each block to its predecessor, which its hash refers to, so they point from future to past blocks.
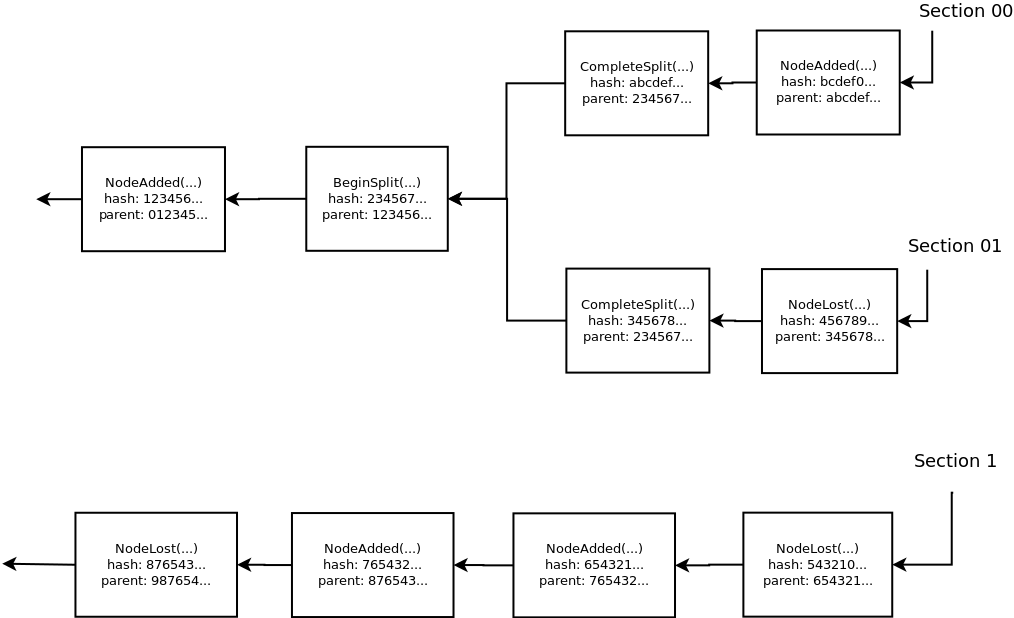
A few types of block are possible, each with a single parent block and at most one child block unless noted:
-
Genesis, the initial network state [no parent] -
Add, recording the addition of a node -
Remove, recording the removal of a node -
BeginMerge, recording the final state of a section before merge -
CompleteMerge, recording the (re)creation of a new section [two parents] -
BeginSplit, recording the final state of a section before split [allows two child blocks] -
CompleteSplit, recording the (re)creation of a new section -
BeginForceMergesee Handling Broken Sections below -
CompleteForceMerge[two parents]
Detailed Chain Specification
The chain is a directed acyclic graph of blocks, of type Block:
struct Block {
/// The section's prefix.
prefix: Prefix<XorName>,
/// The public IDs of all section members.
members: BTreeSet<PublicId>,
/// The type of block, including zero, one or two hashes of previous blocks
/// (see below).
change: BlockType,
/// The consensus algorithm's "view number" when this block
/// was committed.
view_number: u64,
/// The signatures of this block. A block is valid only if it is signed by
/// enough nodes: In the case of all blocks other than `CompleteSplit`, the
/// signatories must comprise a quorum of all (0, 1 or 2) previous blocks'
/// member lists. In the case of a `CompleteSplit`, the signatories must
/// form a quorum of the post-split section members.
signatures: BTreeMap<PublicKey, Signature>,
}
enum BlockType {
/// Record the very start of the network.
Genesis,
/// Record the addition of a new node to the section.
Add {
prev_hash: Digest,
node: PublicId
},
/// Record the removal of a node from the section.
Remove {
prev_hash: Digest,
node: PublicId,
},
/// Record the beginning of a merge.
/// Committed when our immediate neighbour (merge partner) is ready to merge.
BeginMerge {
prev_hash: Digest,
},
/// Record the completion of a merge, with back-references to the merged
/// sections.
CompleteMerge {
/// Hash of `BeginMerge` block from lexicographically lesser section
/// (ending in 0)
prev_hash_left: Digest,
/// Hash of `BeginMerge` block from lexicographically greater section
/// (ending in 1)
prev_hash_right: Digest
},
/// Record the section's decision to split.
/// Blocks of this type are signed by a quorum of the pre-split section.
BeginSplit {
prev_hash: Digest
},
/// Record the completion of a split.
/// Two `CompleteSplit` blocks follow each `BeginSplit`,
/// signed by their respective sections.
CompleteSplit {
prev_hash: Digest
},
/// Record a decision to carry out a force merge
BeginForceMerge {
/// Hash of latest block from our own section (doing the recovery)
prev_hash: Digest,
/// Hash of latest block from the stalled section
prev_hash_stalled: Digest,
},
/// Record the resolution of a force merge
CompleteForceMerge {
prev_hash: Digest,
/// Identifiers of all nodes dropped
dropped: BTreeSet<PublicId>,
},
}
Note that some of this information is redundant, e.g. the added node’s public ID in Add is the difference of the member lists of the block itself and its predecessor. This will allow omitting the member list from most blocks in memory, as it can be computed. To keep the presentation simple, we don’t include that optimisation in this document.
Routing nodes must store the following subset of the chain in their cache: the latest known committed block for their own section and for each neighbouring section, and all ancestor blocks of these latest blocks which are less than MIN_CHAIN_DEPTH distance from a latest block and where the prefix is also for its own or a neighbouring section (this excludes non-neighbouring ancestors from before a merge). At this time it is proposed that nodes do not prune old blocks from their cache when new ones are added or even when relocating to another part of the network, thus MIN_CHAIN_DEPTH is a minimum. It may even be worth preserving the network’s entire history (crude analysis suggests the storage size is not prohibitive, though transfer size on startup likely would be).
The value for MIN_CHAIN_DEPTH will need to be fine-tuned with measurements in a test network: It needs to be large enough to make the probability of nodes falling behind by more than that number of blocks negligible, without creating disproportional overhead. For now, we estimate that 20 should work well.
struct Node {
/// The current sections, reflecting our section table.
latest_sections: BTreeMap<Prefix<XorName>, Block>,
/// Chain cache: known subset of the chain.
chain_cache: BTreeMap<Digest, Block>,
/// ...
}
Block Ordering
A node uses its knowledge of the network to determine the validity and prioritisation of blocks. This knowledge includes recently accumulated messages and blocks from neighbouring sections. The primary, as determined by the consensus algorithm, is expected to propose blocks in a way that is consistent with our view of the network. Blocks get committed when enough nodes agree with the changes proposed by the primary and send their votes, see the Consensus Algorithm section below for details.
A single node starts the network with an initial chain block: Genesis.
When a Begin... block is committed, the corresponding Complete... block is the only possible successor:
-
BeginSplitis immediately followed byCompleteSplitwith the new membership list (or some predicate for calculating which nodes are in this block’s section after the split) -
BeginMergeis followed byCompleteMergeonce aBeginMergeblock from the other section has been received -
BeginForceMergeis followed byCompleteForceMerge(see Handling Broken Sections)
At other times, multiple successors are possible:
-
RemoveifRemoveNodehas been accumulated and delivered (see below) -
AddifNodeApprovalhas been accumulated and delivered -
BeginMergeif a merge is required -
BeginSplitif a split is required
Note that Add and Remove depend on delivery of an accumulated message, which is used to determine whether enough nodes agree to the change that the consensus algorithm is likely to commit the Add/Remove block. This is necessary since nodes view a failure to commit a proposed block as a likely error with the current view’s primary, and thus vote for a view change if a proposed block doesn’t get committed.
RemoveNode is a new message, accumulated by a section and sent to itself when enough nodes vote to remove a node (currently only because the node disconnected). NodeApproval is the existing message accumulated by a section and sent to itself when a candidate passes the resource proof challenge from enough nodes.
Where prioritisation of multiple valid blocks is required, blocks are ordered as follows:
BeginMerge-
Remove, ordered by the name of the node being removed, lowest first -
Add(unique since we can only have one candidate) BeginSplit
This orders blocks from most urgent to least urgent with the goal of stabilising the network as soon as possible. Node removal is prioritised above node addition as removing a faulty node potentially increases the likelihood of reaching consensus during churn by lowering the number of nodes required to reach a quorum.
Consensus Algorithm
Overview
Each section has some corresponding chain segment — a subset of the full chain — which describes that section’s history, back to the last merge or split. Excepting Genesis and the Complete... merge/split blocks, each block is proposed and committed to a chain segment by nodes in the corresponding section learning about events happening to that section. The blocks are proposed by a particular member called the primary, and are only committed to the chain if agreed on by a quorum of members, so that no members of the section can correctly update their copy of the chain segment corresponding to their own section without including the next committed block.
We consider the section members to be the cluster and use a derivative of the PBFT algorithm with small inspirations from Tangaroa to commit new blocks and broadcast them to the cluster. Each new block must be validated by a quorum of the cluster as defined by the member list of the previous block.
Requirements
The consensus algorithm must, given enough time without changing sets of pending changes, ensure that:
- Every node commits the same blocks to its chain segment, i.e. every block has exactly one successor (or exactly two, in the case of section splits),
- Only blocks which are considered pending by a quorum of nodes of the affected section can be committed, and
- All pending changes are eventually committed to the chain or invalidated by other changes and dropped, i.e. without churn, each section eventually reaches a state where no correctly functioning nodes have pending blocks.
Detailed algorithm design
The goal of the algorithm is to make sure that nodes agree 1) which changes to the section’s membership happened and 2) in which order they happened.
The algorithm consists of two mostly independent parts: so-called view changes and the actual synchronisation of the chain segment.
- During normal operation, one of the nodes is the primary, and the others are backups.
- Every node keeps track of a number called the view number. It is included in most of the messages exchanged. Increased view number means that another node is now the primary.
Once a primary is chosen, it takes care of ordering the incoming events and replicating the appropriate log entries in the backups.
- Each node learns of a pending section change independently (for example by receiving a
NodeApprovalmessage or losing a connection to a node). - Whenever there is a new pending change, the primary proposes it as the next block and sends a
PrePreparemessage to all backups. If there are more changes, the primary can pick one and thus decide on the order. - Every backup who receives that message, agrees that this change is pending and hasn’t yet voted for another block in that position in the same view, sends a signed
Preparemessage as a vote to every node in the section. - When a node has received
Preparefor a block from a quorum of the section, it considers it “prepared” and sends aCommitmessage to the whole section. - Only when it has received a quorum of those, i.e. it knows that a quorum of the nodes have received enough votes, it considers the block committed. The block is then part of the chain and cannot be changed anymore.
- If a node has a pending entry, but doesn’t receive an appropriate
PrePreparemessage from the primary for some predefined time, it considers the primary faulty and attempts to initiate a view change, which may result in a new primary being chosen.
The view changes work in the following way:
- When a node considers the primary faulty, it broadcasts a
ViewChangemessage, containing the new view number, the hash of the last committed block along with Commit signatures, and the hashes of blocks later than that which were prepared (along with the proof: the signedPrePrepareandPreparemessages). - When the node that is supposed to be the new primary receives
quorum-1ViewChangemessages, it broadcasts aNewViewmessage with the following content:- A quorum of signed
ViewChangemessages - A set of
PrePreparemessages for the longest chain of prepared blocks received inViewChangemessages, with any remaining pending changes known by the new primary appended.
- A quorum of signed
- Once a node receives a valid
NewViewmessage, it increases its view number, notes the name of the new primary and processes thePrePreparemessages that were included. - The primary for view
vis the node with a name lexicographically after the name of the primary for viewv-1, within the set of the nodes that constitute the section according to the latest committed block. The primary for view0is the node with the lowest name among the nodes in the section. - If a node doesn’t receive a
NewViewafter sending aViewChangefor viewvfor some predefined period, it sends aViewChangefor viewv+1.
The integrity and security of the chain are ensured by extensively using cryptographic primitives like hashes and digital signatures:
- Each block contains the hash or hashes of its parent blocks, thus ensuring that no block can be modified without invalidating all the following blocks (similar to a blockchain).
- Each node signs every block using its own private key. The public keys are stored in the chain, so the validity of each block is determined by the previous chain blocks (thus allowing a third party to validate the entirety of the chain).
Inputs and outputs of the algorithm
The algorithm requires, from the outside:
- A way of scheduling timeouts (using external timers greatly simplifies the code structure)
- A way of sending messages to other nodes in the cluster
- A way of checking whether the pending changes are still valid when new blocks are committed to the chain (some events might invalidate pending blocks, for example a split can invalidate a “node added” event when it concerns a node that will belong to the sibling section after the split).
- A chain structure in the form of a DAG.
The user code is required to call the algorithm in the following cases:
- When there is a timeout
- When a message regarding consensus has arrived from another node
- When the node learns of an event that requires the section to reach agreement
Each of the methods called in these cases returns a sequence of hashes of the newly committed blocks, so that the node can update its state according to the data contained in these blocks.
Differences between the proposed algorithm and PBFT/Tangaroa
Terminology note: what we call a “chain” and “blocks”, the consensus algorithm papers call a “log” and “entries”.
- Tangaroa and PBFT both work on a linear log and assume constant cluster membership in normal operation - our algorithm is a solution for agreeing about the changes to the cluster membership.
- Related to the above: Tangaroa and PBFT both use indices to identify the positions of the entry in the log. Since our log/chain isn’t linear, it’s not entirely feasible in our use case, so we identify the entries just by the hash and only use a notion similar to indices for the purpose of determining the ordering of two given hashes.
- In the PBFT paper, the
NewViewmessage containsPrePreparemessages for a set of entries that is determined by merging the sets of prepared entries from differentViewChangemessages. Since the blocks in our algorithm contain the hashes of their parents (similar to Tangaroa or blockchains), merging of differing chains is not feasible, so we just choose the longest chain. - Tangaroa uses an election mechanism instead of view changes - every time the leader (analogous to the primary in our proposal) is considered faulty, nodes propose themselves as candidates and vote. The node with a quorum of votes becomes the leader for the next term (which is similar to PBFT’s view).
- Tangaroa uses only two rounds to commit an entry: it’s proposed by the leader and when a quorum of signatures is gathered, it’s considered committed. This works in a setting where we have an external client that issues requests and waits for responses, but it’s not enough to satisfy our requirement of a 3rd party being able to independently validate the chain - there are ways of presenting a forged chain that will be accepted. In order to achieve our goals, we adapted the 3-step algorithm from PBFT.
Possible alternatives
- Instead of using the view change mechanism from PBFT, we could use Tangaroa’s elections. In that mechanism, however, it is possible for malicious nodes to become leaders repeatedly and thus stall the section. Working around this issue would be more complex than just cycling through all nodes with view changes.
- We could return to the idea of indices by assigning to each block the number of blocks along the longest path in the DAG between that block and the genesis block. This is well-defined and constant for each block, and unique along every path in the DAG. Such indices wouldn’t be unique across paths, but this can be solved by identifying a path in some way as well (for example by the prefix of the section the path concerns).
Message Flow
Connecting
ConnectionInfoRequests are always ignored if we are not expecting the sender. We always send them when we expect new contacts. That way, the node that learns about the change last will send a request that won’t get ignored. For example, node n gets added to section A via Add(n) and learns about neighbouring section B. n sends ConnectionInfoRequest to each node in B, but assuming this reaches the nodes before they receive the section update containing Add(n) they will all reject it. When they do receive Add(n) they send ConnectionInfoRequest themselves (this always gets sent by both connecting nodes); since n has already sent the message it knows that it needs a connection to each node of B sending ConnectionInfoRequest and so n replies.
Section Membership
Conditions currently leading a section being merged or split will instead lead to a BeginMerge or BeginSplit block being proposed and, if agreed by a quorum of nodes, committed. Only once a merge or split block is committed do we make changes to our local state.
For node additions, we accumulate a NodeApproval message, wait for an Add block to be committed and then act upon the addition locally. Similarly for node removals, we accumulate RemoveNode, wait for a Remove block and then make the change locally, including disconnecting from the node.
When a node commits a new block (for its own section or a neighbouring section) via the consensus protocol, the block is added to the local cache and the data structure pointing to the latest known blocks for each section is updated. Similarly, if a self-validating (committed) block is received via an update, and appears valid, the local state is updated. If a block appears valid but the parent is not known (not in our cache), we extract the prefix and request an update from our section via the block exchange protocol.
When a block for our own section is committed to our chain, we send a section update containing the new block to all neighbouring sections.
For every new committed block which we add to our cache (for our section or any neighbouring section) we sign the digest and send the signature to our section. This is for hop message validation and replaces the current “signed section lists”.
Updates to our Own Section
When Add(n) is appended to our chain cache, we insert the node in our section table. If the node is joining our own section, we send the latest blocks from our chain for each current section up to a depth of MIN_CHAIN_DEPTH to the new node n. The new node n considers any block sent by a quorum of nodes to be valid as well as any which are a self-validating successor of another valid block. The new node n can only build its section table and start normal operation once it has at least one chain block for each neighbour.
When Remove(n) is appended to our chain (for our own section or a neighbour), the node n is removed from our section table and disconnected. If the node n receives a valid Remove(n), either it is relocating (in which case it continues with the relocation) or has been kicked out but still has some connectivity, and should then disconnect and either shut down or restart.
BeginMerge terminates a chain segment and can only be succeeded by CompleteMerge; if BeginMerge is committed to our own chain segment then no other proposals are accepted. The primary of the lexicographically lesser section (p0 for some p) becomes the primary of the merged section. It should propose the CompleteMerge once both sides have committed BeginMerge. If it fails to do so the normal view-change mechanism chooses a new primary to propose the change.
When CompleteMerge is committed it begins a new chain segment. Each node in this section updates its section table (own prefix and section merge) and sends a direct message to each member from the other merged section containing the chain blocks within MIN_CHAIN_DEPTH of every current section block which was not previously a neighbour of the other section. Nodes can add blocks from the new neighbours’ subset of the chain to their own cache when a quorum of nodes from the merged section send the same block, similar to how a joining node initialises its table. Once each neighbour prefix has at least one chain block the newly merged nodes may resume proposing section changes.
BeginSplit is another block terminating a chain segment, and is immediately succeeded by two different CompleteSplit blocks; when BeginSplit is committed for a node’s own section, the existing primary continues as the primary on its half of the split, and the lexicographically first node of the other side of the split becomes the primary for that side. These two primaries propose CompleteSplit blocks to their new sections, or they are replaced via a view-change.
CompleteSplit starts a new chain segment. When committed, the section table is updated: split the old section into two new ones, update our section’s prefix if the splitting section is our own, and disconnect from any sections which are no longer neighbours.
If BeginForceMerge is appended to our chain segment, it means we are about to forcibly merge with another section, S. We attempt to connect to all neighbours of S, determine which nodes are still connected, then commit CompleteForceMerge (see Handling Broken Sections for details).
When CompleteForceMerge is committed, we handle it like CompleteMerge; the block already contains details of which nodes are members of the merged section.
Section Updates
Whenever a block is committed for our own section, we send a Section Update as a ManagedNode to each neighbouring section (as a PrefixSection) with the new block(s). This is sent immediately when a new block is committed, but even so there could be multiple new blocks committed at the same time: CompleteSplit follows BeginSplit immediately, CompleteMerge might follow BeginMerge immediately, and it is possible that our node is behind the section and learns about multiple new committed blocks at the same time.
Updates from Other Sections
Blocks from neighbouring sections are added to our chain if valid in the same way as those from our own section, and if valid trigger updates to the corresponding sections in our routing table.
If we receive a BeginMerge update from our sibling — our prefix with the last bit flipped — and we have not yet proposed a corresponding BeginMerge, then we propose this block for our section. This is required even if the merge does not appear necessary by other criterion, since the other section is not able to cancel a merge after committing BeginMerge.
If we receive a BeginMerge update from our sibling and have already committed BeginMerge for our section then we create and commit a CompleteMerge block as a child of these two BeginMerge blocks (including all members in either of the two BeginMerge blocks). This is done directly (no communication with other members required).
If we receive BeginMerge from a section which is not a sibling we add it to our cache but take no special action. We should receive the succeeding CompleteMerge block automatically.
If we receive BeginForceMerge from our sibling, then presumably our section is broken (see Handling Broken Sections). In this case we should receive a ping from each member of that section if we are still connected, and then a CompleteForceMerge block. In case our section is still responsive after receiving BeginForceMerge, we should commit BeginMerge and then merge like normal.
If we receive BeginForceMerge from another section we take no special action, as with BeginMerge from another section. (In the case BeginForceMerge was committed by a section we were not previously connected to but is the sibling of one of our neighbours, we should already have connected when we receive this block, thus special action has already happened.)
If we receive CompleteForceMerge from our sibling, then if we are included as a member in the CompleteForceMerge block we become part of the merged section and update our routing table; if not, then we restart (dropping our node from the merged section could be entirely valid if we were disconnected briefly; it may still be worth tracking such events however).
If we receive CompleteForceMerge from a different section, we handle it like CompleteMerge except that we will need to disconnect from any nodes dropped by the merge (if that section was previously a neighbour).
Other updates from neighbouring sections (to add, remove or split) could trigger a split or merge in our own section, and may cause us to send connection requests or disconnect from nodes, but otherwise do not directly affect our section.
It is not essential to ensure that section updates reach every neighbouring node (e.g. nodes recently added to neighbouring sections may not receive our section’s updates); instead the processes are designed to tolerate small discrepancies in the version of neighbouring sections. For example, a section can only split if its direct neighbour prefix (with last bit flipped) has already split or has a minimum number of blocks; our section may only split when enough nodes in our section believe the direct neighbour meets this criterion.
Alternatives
Section Updates without batching
We could disable batching multiple blocks in the same Section Update. In this case each node should send the same updates, so we could send the Section Update message as an accumulated message from our Section to each neighbouring prefix, which is O(n) instead of O(n^2) in section size n. However, we would need to be careful about accumulation when our section splits or merges.
Resource Proof
(This is mostly a separate proposal which could be implemented before or after the main Chain proposal.)
In the current routing code, a joining node must pass a resource-proof test with a quorum of nodes already in the section, and these nodes attempt to send NodeApproval to their own section as an accumulated message, which is O(n), but requires nodes use a timeout to synchronise the time at which they attempt to accumulate this message (resource proofs may complete at different times).
We propose instead that when a candidate starts a resource proof challenge, it sends some token data; the tuple (candidate_id, latest_block_identifier): (PublicKey, Digest) should suffice (in order to implement this without the Chain, latest_block_identifier could be replaced by the recently implemented VersionedPrefix or simply a timestamp). The candidate is rejected if the “time” part of this data is not from the recent past; otherwise it is given the resource proof challenge. When a node is satisfied that the candidate has passed its challenge, the node signs this token data and sends the signature to the candidate.
Once the candidate has enough of these signatures (at least a quorum, perhaps with error margin), the candidate sends the token data and signatures to all members of the section. Nodes check that there are a quorum of valid signatures from the section’s current membership and that the “time” part of the token data is current (e.g. not more than 20 blocks behind the section’s latest chain block / version, or more than 3 minutes in the past), then use their consensus mechanism to propose the Add block (or accumulate NodeApproval). (Even without chain blocks, a second consensus mechanism is necessary, since the signatures might satisfy a quorum according to one version of the section’s membership but not later, e.g. if one of the signing nodes was removed).
The advantages of this mechanism is that the candidate is responsible for synchronisation of the second consensus step (instead of using timers to synchronise accumulation, or proposing Add blocks which have a high chance of not being proposed by enough other members to be agreed).
Secure Hop Messaging
This part of the proposal describes how the security of hop messaging can be improved by establishing a chain of trust between the senders and recipients of hop messages.
When a new block is added to a node’s chain cache for a neighbouring section, the node signs the block and sends the signature to each member of its own section. Each node collects these signatures in its block signature cache:
block_sig_cache: BTreeMap<Digest, BTreeMap<PublicId, Signature>>
That way, each section A will, for each neighbouring section B sign each chain block of B that it learns about.
When a node is accumulating signatures for a signed message, it sends the message as soon as it has at least one block, relative to which the message’s signatories have a quorum. If multiple blocks qualify, it picks the latest one. This block is inserted into the signed message before sending.
When a node in a section B relays a signed message coming from its neighbour A, it checks for its own signatures of the block x that A inserted into the message. B appends the latest block y of B, such that a quorum of the members at y have signed x, and inserts these signatures, then relays the message. If such a block y does not exist, the message is dropped.
This way:
- Every node in the target group or section will accept the message if the relay node (i.e. the first node in the section to receive the message) did: the relay inserted a validating chain block signed by a quorum of the section.
- Merges and splits don’t break validation since the last few blocks before the change are still available in the chain and can be used for validation.
Handling Broken Sections
Several constants are needed for broken section handling. Provisional values for these are listed:
-
HEARTBEAT_DUR= 1 minute -
HEARTBEAT_TIMEOUT= 3 ×HEARTBEAT_DUR -
PING_WAIT= 30 seconds -
MIN_FRAC_RESPONSES(TBD) -
MIN_PING_RESPONSES(TBD)
Determining optimal values for these parameters will be done experimentally.
Detection
In the absence of section updates, each section sends its neighbours a heartbeat message, sent as an accumulated section to section message, such that the maximum time between messages should not exceed HEARTBEAT_DUR.
If no update or heartbeat message is received from a neighbouring section for HEARTBEAT_TIMEOUT, that neighbour is considered to be broken.
Resolution
Without loss of generality, consider that the broken section is p0 (here p is a binary sequence, and p0 is the same sequence with 0 appended, and this sequence is the section prefix). We consider p1, the sibling, to be the section which should take action.
If our section is p1, the sibling, we first commit BeginForceMerge and connect to all sections neighbouring p0 which aren’t already connected.
Next, we establish which nodes of p0 are still reachable:
- Each node in
p1sends a ping to each node ofp0 - Nodes in
p1waitPING_WAITfor ping responses - Nodes in
p1broadcast a signed message to their own section with the digest of theBeginForceMergeblock and the list of nodes in the broken section which are still reachable according to ping responses. - Once the primary (current primary in consensus algorithm) of
p1has receivedMIN_FRAC_RESPONSESof these broadcast messages, it proposesCompleteForceMergewith a list of nodes considered reachable: those who responded to pings to at leastMIN_PING_RESPONSESof the nodes in our section, according to the signed responses this primary has received from members of its own section.
The primary broadcasts this proposal and the signed broadcast messages which justify this still reachable list back to its own section, then attempts to commit this block. Nodes receiving this message should update their list of signed broadcast messages if appropriate, check whether the still reachable list of nodes in the CompleteForceMerge block matches their own calculations, and if so vote for this block. If not, the primary is considered faulty and the node attempts to initiate a view change.
If our section is not p1, then we add this section (p1) to our Section Table and attempt to connect.
If a force merge happens, this saves us connecting to the section later, and lets us monitor the section in case the merge doesn’t happen. Since we are now connected to this section, we should receive updates and heartbeat messages from this section; if this doesn’t happen we can consider that this section is also broken. If both p0 and p1 are broken, we consider the prefix p broken and repeat all broken-section handling logic on this new prefix.
Analysis
Section p1 determines which members of p0 to keep. Considering that p0 was broken, it must have some “bad nodes”, somehow not performing correctly.
In the case that the “bad nodes” are merely disconnected good nodes it should be relatively easy for p1 to agree which nodes to drop and have a high chance of resulting in a functional merged section p (assuming nodes don’t continue dropping at a high rate).
In the case the “bad nodes” are slow good nodes, perhaps hit by a surge of work or network contention, it is unpredictable whether “pings” from p1 will reach these nodes and be answered, thus it could be harder for p1 to reach consensus on which nodes to drop (if the slow nodes each answer only some of the pings). This might still result in a successful merge/recovery, might at least temporarily prevent any merge from happening, or might as above result in a merge which doesn’t drop the bad nodes and could cause the merged section to be dysfunctional (though, unless pings are very easy for the “slow nodes” to answer, the merged section is more likely to be functional).
In the case the “bad nodes” are malicious, they could all appear perfectly good to p1, thus the merge may not drop any nodes. Assuming that p1 previously had a majority of good nodes and p0 did not have any majority, the section p will not have a majority of malicious nodes but may also not have a majority of good nodes.
What if instead p0 was not broken but p1 was compromised? In order to commit a fraudulent BeginForceMerge, the section p1 must have enough malicious nodes to satisfy quorum, thus these nodes can commit a CompleteForceMerge with any list of “still reachable” nodes they want. Since the compromised section can commit any Add block in the same way, an attacker with a single compromised section could add enough malicious nodes to satisfy the workload and use force merges to take over neighbouring sections, dropping enough other nodes to maintain a compromised quorum.
Block Exchange Protocol
This part of the proposal describes the protocol that nodes can use to exchange blocks.
Message Definitions
The protocol is comprised of three messages:
-
BlockRequest, which requests blocks after a given point. -
BlockHistoryRequest, which requests before a given point, or backwards from the present point in time. -
BlockSet, which conveys blocks to another node, optionally in response to aBlockRequestorBlockHistoryRequest.
Their definitions are:
/// A block request is a request for blocks *after* a given point, provided on a
/// best-effort basis.
struct BlockRequest {
/// Digests in our chain that we would like to obtain the successors of.
start_hashes: BTreeSet<Digest>,
}
/// A block history request is a request for blocks *before* a given point,
/// provided on a best-effort basis.
struct BlockHistoryRequest {
/// Prefix of the section that we would like to request history for.
prefix: Prefix,
/// Digest of the oldest block that we already have for this prefix.
///
/// If we have *no* blocks for the prefix, then the digest should be `None`,
/// and the receiver of this message should send us historical data backwards
/// from their latest block relevant to this prefix.
digest: Option<Digest>,
}
/// A block set is a set of blocks, with optional signatures from the sender's section.
///
/// The receiver can derive the ordering from the block data.
struct BlockSet {
/// The blocks.
blocks: BTreeSet<Block>,
/// Signatures from the sender's section, to enable secure hop messaging.
///
/// This map should be empty if the blocks belong to the sender's own history,
/// in which case no further signatures are required.
signatures: BTreeMap<Digest, BTreeMap<PublicId, Signature>>,
}
All three messages are sent directly between peers.
BlockSet messages contain a maximum of MAX_BLOCK_SET_SIZE blocks. The exact value is to be determined based on expected block size (in bytes), and the ideal size for messages sent via Crust.
Sending Blocks Pre-emptively
In the following situations we know exactly which blocks are required by a neighbouring node, and we can convey them via a BlockSet message:
- When two sections merge. Each section collects the
MIN_CHAIN_DEPTHblocks for neighbouring sections that their sibling was not previously connected to. These blocks are bundled into aBlockSetmessage and sent directly to each node in the partner section. For example, if sections 00 and 01 merge to form section 0, then section 00 would send blocks for 10 to the nodes formerly part of 01. - When a new node joins. Our section sends
MIN_CHAIN_DEPTHblocks to the joining node for each known section. The new node can later request more history using aBlockHistoryRequest, described below.
Requesting New Blocks
If a node n has received a message referring to an entry hash h that it knows nothing about, it first determines the prefix p which the hash is meant to be for - for example, by pulling it from the section update that refers to h. It then looks up the prefixes which match p, and places the latest digests for each of these prefixes into a BlockRequest message:
let relevant_prefixes = every prefix in our chain that matches p;
let message = BlockRequest {
start_hashes: {latest_digest(prefix) for prefix in relevant_prefixes},
};
Node n sends this message to every node which appears to be part of one of the relevant sections. The logic here is that if n has missed a merge or split, it should contact the nodes which are likely to be in the post-merge/split sections.
For example, if we get a section update for P(0) but only have P(00) and P(01) in our latest_sections, we should contact all the nodes in P(00) and P(01) and get updated on the intervening history from both sides (in particular, we need to verify the merge).
A node m that receives a BlockRequest message looks up the digests in its store, and responds appropriately:
If entries for any of the digests are found, we take the prefixes from the entries, find all matching prefixes in our latest_sections, and traverse backwards from these prefixes’ digests until we’ve hit every digest from request.start_hashes. We take up to MAX_BLOCK_SET_SIZE of these entries and send them in a BlockSet message to the requester n. In the case where there are more than MAX_BLOCK_SET_SIZE blocks that we could send, we favour older ones so that n can verify them.
If n receives a BlockSet response, it adds the valid blocks therein to its store. It also signs member lists and hashes from the new blocks and sends its signatures to its own section to enable secure hop messaging.
Requesting Historical Blocks
In some situations, it’s desirable to retrieve history prior to some block, or all the latest history for a given prefix. Two such cases are:
- If we are a joining node, our section will have sent us some of the history for our section, but not all of it. In this case we send
BlockHistoryRequests to our own section, containing the digests of the oldest blocks in our section’s history. Our section responds by sending back the requested history, up to the maximum ofMAX_BLOCK_SET_SIZE. - If we are a node on one side of a merge, and miss the
BlockSetmessages from the other side, we need a way to obtain the recent history of new neighbour sections. In this case we sendBlockHistoryRequests to our own section, one for each neighbour prefix for which we have no history. We don’t know any blocks from neighbours in this case, so thedigestfield isNone.
In contrast to a BlockRequest message, when a node responds to a BlockHistoryRequest it favours sending newer blocks if the number of total blocks would exceed the MAX_BLOCK_SET_SIZE. This is so that the requesting node can connect the blocks it contains to its chain, which it is building out backwards (rather than forwards, as in the case of a BlockRequest).
Optimisations
- A node could wait a short while before it sends a
BlockRequest, in case it finds out about the missing update(s) in the meantime. - A node could send requests to just a few neighbouring nodes initially, trying more and more nodes until it receives an answer or runs out of nodes to ask.
- Add an optional size limit to the
BlockHistoryRequestthat allows nodes to set how many blocks they would like to receive. -
BlockSetsize could be determined dynamically based on the load upon the node. - It may be possible to speed up replies by using some an index on the chain. Traversing blocks forwards rather than backwards would speed-up responses to
BlockRequests, as we favour older blocks.
Bootstrapping Trust
Joining nodes and clients shouldn’t have to trust the nodes that claim to be their section Y. The following mechanism will allow them to verify the section, as long as they know any block good_block from anywhere in the network.
For this to work reliably, each node should store at least the subset of the chain concerning its own section’s history indefinitely.
- The client or joining node
Csends aSectionProofRequest(good_block, y_block)with the last block ofYtoY. -
Yverifies thaty_blockis indeed in its cache and sends theSectionProofRequest(good_block, y_block)on to a sectionZwith an address belonging togood_block. -
ZbelievesYthaty_blockis one of its blocks, since the request was a secure section-to-section message. Every node inZresponds toCwith aSectionProofResponse(y_block, opt_blocks): If it hasgood_blockin its cache,opt_blocksis the complete chain segment fromgood_blockto the currentz_blockofZ.
If C receives at least one such chain from good_block to z_block (including all the signatures), it can now trust z_block, too. If it received responses containing y_block, from a quorum of the members of Z, that validates y_block.
Limitations and Security
Security of the network depends on each section behaving correctly, which is ensured by the network distributing nodes throughout the network automatically, such that an attacker cannot choose where in the network any nodes he runs will join, and a brute force attack would require running a significant proportion of the nodes in the network to have any real chance of success. To investigate brute-force attacks (so called Sybil attacks), we created a simulator framework. An attacker would need to control a quorum of the nodes within a section to control that section.
The broken section recovery mechanism could be used as a weapon allowing a section controlled by an attacker to take over more of the network, even up to the point of taking over the entire network if the attacker had enough resources to handle network load; this is a known limitation, but necessarily any mechanism to recover from a state where no consensus is possible must reduce security. This does not necessarily mean the system is less secure than a network using a less strong form of consensus, and is only an exploit if an attacker can control one section in the first place.
A further limitation is that the extra message handling required to establish consensus on each new block may add some delay, especially if there is a need for a view change. This is not seen as a major concern because in a running network, the work involved in handling client requests is expected to be far greater than the work involved in managing churn (nodes add, lost, section split and merge).