This topic is for discussions about about creating an alternative to the SAFE FileContainer / flat filesystem by using a new FileTree CRDT. Issues such as:
- how to represent the tree (e.g. path or node style)
- suitability of FileTree CRDT for SAFE Network (cf. performance, security, robustness)
The aim is to allow multiple simultaneous edits of the FileTree and provide a file system API which is sufficiently close to or compatible with POSIX, that regular apps will be able to access a FileTree mounted as a FUSE (*nix/OSX) or Windows Drive. This was introduced in the following extract from this week’s development update.
Development Update 16 July 2020 (link)
We have begun to explore possible design improvements for the SAFE File API.
In particular, a recent research paper (and video see 35:30) caught our attention that could dramatically improve performance, help simplify our API, and solve collaborative editing challenges. The paper is titled A highly-available move operation for replicated trees and distributed filesystems and it details a formally proven CRDT Tree data type that is suitable for filesystem usage and, being eventually consistent, solves a longstanding move operation problem that affects even Dropbox and Google Drive when dealing with concurrent updates. It is also suitable for working offline.
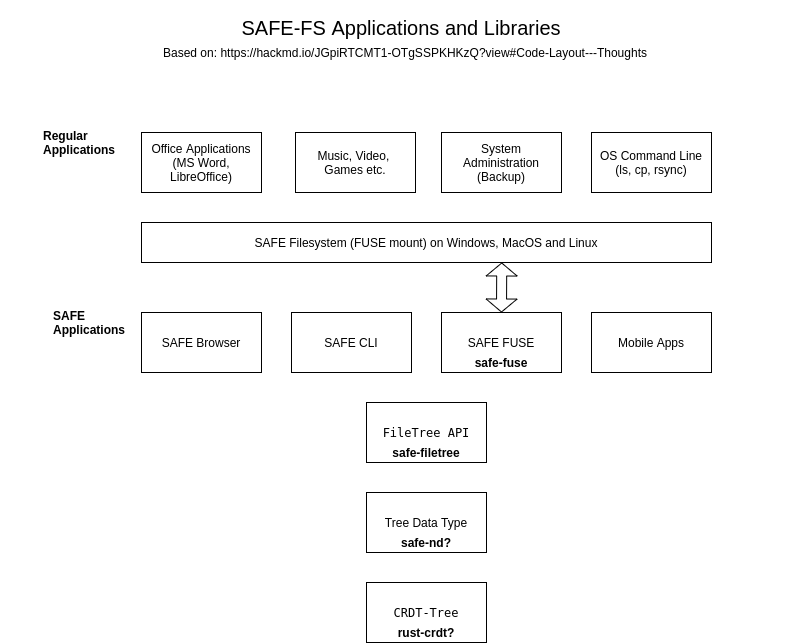
The core design idea is to add
Treeas a SAFE Data type, and implement aFileTreeas a specialisation, just asFileContainerhas been a specialisation ofSequence. The important difference is that each Directory and File is stored individually in theTree, instead of all serialised together as a flat JSON map in a singleSequenceentry. This makes updates and retrievals much more efficient for any non-trivial directory structure.Going further, we would like to incorporate elements of Safe.NetworkDrive for fast local access and offline usage, as well as native file system integration via FUSE.
To be clear, the idea is that SAFE apps could access the File APIs directly if they wish, but non SAFE apps could still interact with SAFE files via a local mount. This would mean that tools such as rsync could be used easily, file explorers, etc.
For the moment, this remains brainstorming and high level design. There’s a lot to solve. A first challenge would be to implement the
CRDT-Treealgorithm in Rust. It presently exists only in the form of Isabelle/HOL formal logic. If any community member is proficient with Isabelle/HOL and could help translate it to Rust, or even pseudo-code, that could help speed things up.
Resources and Related work:
- CRDTs: The Hard Parts — Martin Kleppmann’s talks (link). See this post for notes about this talk with time stamps.
- A highly-available move operation for replicated trees and distributed filesystems, Kleppmann et al, 2020 (move-op.pdf)
- Code data etc related to the move-op paper (trvedata/move-op)
- Local-first software: You own your data, in spite of the cloud (link)
- Rust implementation of automerge (automerge/automerge-rs)
- Release: SAFE.NetworkDrive on Windows v.0.1.0-alpha.1 (SAFE forum announcement, March 2019). A stand-alone filesystem for SAFE Network on Windows using Dokany FUSE. (More on the implementation in this post).
High Level Goals
Please update as needed:
- create a more flexible filesystem API than we presently have.
- provide a FUSE abstraction for legacy apps to utilize SAFE filesystem.
- avoid apps blocking on network requests (as much as possible)
- enable working with filesystem offline
- handle concurrent modifications well. (strong eventual consistency)
- as performant as possible within above constraints.
Features
At a more detailed level:
- integrate with NRS and SafeURLs: any content held inside a FileTree should have a URL, and so for example be accessible via SAFE Browser.
- a FileTree and each contained item must be versioned, and any version able to be referenced via a SafeURL.
SAFE FUSE APIs (very early draft)
The outline of a possible SAFE FS API based on the FUSE APIs is now available:
- SAFE FS Proposed APIs. Feedback welcome here or on github.
Miscellaneous
- Thoughts on FUSE low-level versus FUSE high-level APIs (post)
- Brainstorming SAFE Network FUSE by @danda (hackmd)
- Survey of RUST/FUSE FileSystem Libraries by @danda (hackmd)
Summary of Issues to Explore - See SAFE Forum post by @danda
This post is a Wiki so additional references or sections can be added by anyone.