Nice calcs. I think they highlight that we need to be very careful/conservative with how we define inode metadata, so as to minimize the bytes/node. It will be instructive to look at how other filesystems do this.
As for the crdt metadata, I believe optimizations will be made over time. For example, in the CRDT: Hard Parts video, they present an algo for compressing the crdt metadata for the automerge project by approx 200x, if I remember correctly. I suspect something similar could be done with the tree crdt data.
First though, we need to prove this thing works, at all. As for @dirvine’s opinion on caching locally and working offline, I’d rather not speak for him.
ps, on linux one can see the number of inodes in use per mount with the df -i command, eg on my laptop:
I agree compression of CRDT metadata is possible, but the 200x figure was versus JSON encoding, so we looking at something very much smaller.
IIRC they managed to get the log down to a little less than one byte per mutation (for sequential CDRT rather than tree-move). That’s impressive but could still add up over time.
I’m not sure how much we can save of file entry metadata. Anything is useful, but we’re probably not talking orders of magnitude so I don’t think these economies solve the issue and it remains an unanswered question I think.
On other topics I’ve started on both the safe-fuse stubs and looking at your crdt-php.
I’m not sure what the issue is here. For ex, is there a reason why inode/u64 can’t be used as the id (for a hashmap of FileTree objects), and the IData xor address of a file be part of the metadata for the file (ie held in the the FileTree object for the file)?
I agree that’s sensible and as far as I can tell does everything we need, will work with path or inode API, could support hard links if we believe they can be handled in a TreeCrdt (to be determined).
I’ve been thinking a bit about the architecture today and some of the questions I had. I think we can probably handle large numbers of nodes later. For ex by limiting the FileTree size, and nesting each subtree by treating it like mounted subdirectory, but maybe other ways too.
I’m still thinking though! I’d like to look at supporting file seeking read and write with a memory cache of 1MB blobs (multiple blobs per file) in the way Syncer does, but with this part inside the SAFE FS API rather than SAFE FUSE so it will be available to all FS apps.
This would give us file and FileTree cached in memory, synced to SAFE (if you implement it the same way as the Sequence CRDT), and a pretty POSIX compliant filesystem API as well as a FUSE mount.
If that sounds sensible I could work on the FUSE to SAFE FS API, and the file operations of the FS API. You could work on the TreeCRDT and FileTree side of the FS API, client libs API and core.
yes, I think the cache should be inside the SAFE API. However, I don’t have a solid design for it in mind yet. Do you have a clear grasp of how syncer’s approach is similar or different to that of Safe.NetworkDrive, which is log/event based? I think our FileTree lends itself to the latter approach, via the operation log. Our challenge may be more one of safely pruning the log than of caching.
That sounds fine as a starting point. An important area design-wise will be defining the SAFE FS API. We need to get that nailed down pretty well on paper before implementing. The requirements of the FUSE layer can help to mold/shape the FS API, so I’d suggest you start with implementing a stubbed (or in-memory) FUSE layer, and then document the underlying APIs you will need to make it work.
I agree (about defining the APIs). I only know the event based approach from memory of Edward’s forum posts. Syncer creates a cache of 1MB blobs for each file, held in a hash map until written to storage. I think that is relatively clean and easy to implement, and to sit both the POSIX like FS API on, and FUSE on top of that.
I don’t know how different the implementation would be with Edward’s approach, or what the pros and cons of each is compared to the other. It would be good to have a summary of that, and any thoughts on how it would fit with the Tree CDRT.
I think the FS API should not be affected either way though, so we can outline what that should look like, at least as an ideal to aim at, and then consider how to implement the SAFE FS side of it. That would not affect the FUSE implementation which will fit easily if we are reasonably POSIX compatible.
The reason I like Syncer’s design is because it already has key POSIX features that suit FUSE very well, including multithreaded file open for non blocking read, plus one open file write. This was lacking in the old SAFE NFS API and I suspect caused difficulties for my earlier FUSE SAFE Drive with applications like git. It’s also already written in Rust.
Maybe there are also good reasons for choosing an event driven approach? I’m also wondering if one aspect (TreeCDRT) might suit an event log, while the other (file open/seek r/w) would suit the blob cache approach. So maybe we should also sketch out boundaries between these areas. They are quite distinct in Syncer so I suspect it would be feasible too extract the part from there and integrate it with the tree/metadata part you build.
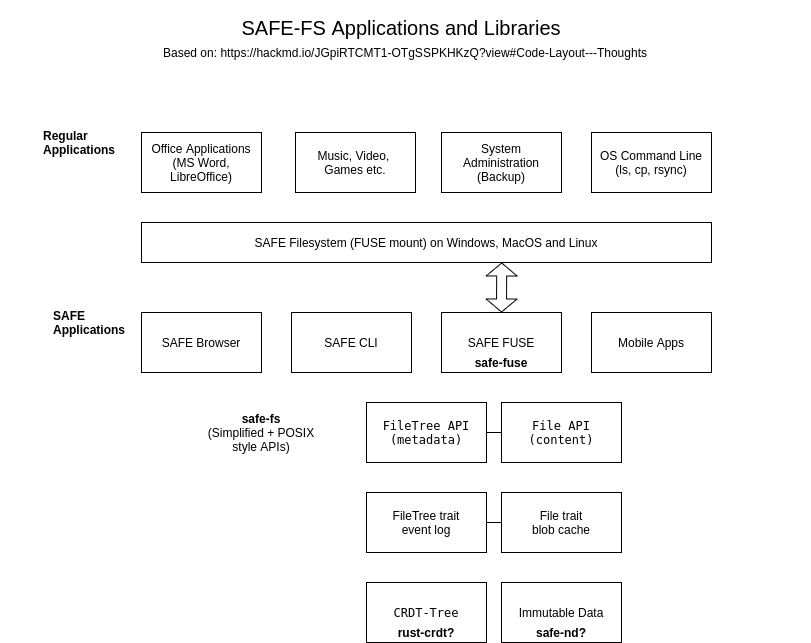
UPDATE: I made a few edits and additions, particularly the last two paragraphs and updated the diagram to illustrate the suggestion (below). Today I plan to look at the FUSE ops to implement and map them to safe-fs APIs (simple and POSIX) so I can think about the FileTree (metadata) and the File (content) boxes and how they interact.
@danda I have a draft of the SAFE FS APIs. I assume we’re going to go through an RFC process so not sure when or how you plan to do this. I could get it ready for that or just publish it as is for now. Any thoughts?
It is just a first draft at this point so I need to think about how well it fits the latest diagram and the division of work between FileTree and File traits that I’ve suggested. I’ve based it largely on the FUSE ops which I think fit POSIX pretty well, but want to review it against other FS implementations and can get on with that.
I’ll also create the stubbed FUSE implementation using Syncer as a template. Is there anything you plan to do with this in the short term, so I can make sure it’s suitable for that?
So we have an issue with the u64 as identifier in the crdt-tree.
The tree algo requires that node identifiers are globally unique across all replicas, ie something like a UUID, which is 128 bit. This is necessary for the log operations to merge without conflict, else would not be crdt. Any replica can create an ID. Eg, we could think of a laptop, desktop, tablet, and mobile phone all operating on the same FileTree mount-point.
A random u64 is not sufficiently unique to really qualify as a globally unique identifier.
Actually, this raises a question: in the Fuse API, who actually creates new inode IDs: fuse/kernel or the filesystem implementation? @happybeing do you know?
Assuming we use a UUID internally, for fuse we are back to the issue that inode numbers must somehow be mapped to the UUID and back.
I’m pretty sure it’s created by the filesystem and only applies for the low level API, but will confirm this.
Doesn’t this only apply if we use the lower level FUSE API? If we use the path API, we could map paths to whatever internal ID we choose our use paths directly. I think this mapping will live in the FileTree, and probably not need to be exposed.
I think there’s only reason to use the low level API if we can support hard links, which is TBD.
It’s late so I’ll look again tomorrow.
I’ll publish the draft API doc once I’ve reviewed it.
Indeed, this was my original thinking, as I was suggesting we start with the path API before. But then I forgot about the UUID requirement temporarily.
I think that’s the main reason. Also there may not be a solid path based fuse rust implementation right now for windows.
Neither is necessarily a showstopper. We can defer the decision for now.
I’ve taken a detour around the FUSE implementations while learning about Windows support and here’s my summary wrt high and low level approaches.
Based on the summary below I’m inclined towards the low-level FUSE route if we can map paths to inodes because we have more consistent Rust based options across Linux/MacOS/Windows, and can support hard links on all but Windows. I’m not so familiar with the low-level API though, so would need to look at that in more detail if the inode issue can be handled.
Using Path Hash as inode
On the last point, one option would be to create a u64 hash of the path for use as the inode. This would avoid the need for a map as all FS access will begin with a path to get to the inode of a file, directory or symlink and the FileTree doesn’t need to know about the path once it knows the inode.
So I did some calculations. Chances of a collision appear very small, one in 2^64 per path, so for a filesystem with:
a billion files (10^9 ~ 2^30) would be one in 2^34 or one in 17,179,869,184 = very safe
average file size 20 bytes would total ~60GB (18GB for content and maybe >40GB for metadata)
average file size 1KB would total ~ 1TB (960GB for content and maybe >40GB for metadata)
ten billion files (10^10 ~ 2^34) would be one in 2^30 or one in 1,073,741,824 = safe enough?
average file size 20 bytes would total ~220GB (180GB for content and maybe >40GB for metadata)
average file size 1KB would total ~ 9TB (9,600GB for content and maybe >40GB for metadata)
a thousand billion files (10^12 ~ 2^40) would be one in 2^24 or one in 16,777,216 = unsafe but still useful for archiving as some files would be trampled eventually but on SAFE old data is never overwritten so you could always get it back.
Caveats: I plucked all the ‘typical’ figures out of the air and have been known to get maths badly wrong, so both need checking! (ref: table of powers of two on Wikipedia)
Look the inode up in the FileTree
Alternatively we can just look up the path in the FileTree to get the inode as this is not a particularly frequent operation, not that expensive (one lookup per level to find the directory, get the directory contents which could be a hash-map, and get the inode from that). If we’re keeping the FileTree in client memory these operations are all in local memory.
I think we can start with one and easily switch to another as well. So I’m voting for the low-level API at this point. I’ve made a summary of both and how they could map to the SAFE FS API here:
Note: cxfuse (github, by crossmeta) is an additional option for Windows, both high and low level FUSE APIs and has commercial support, but no source code for the libraries (BSD license).
High Level API
Pros:
easier to implement and mapping paths to inodes taken care of
Cons:
no pure Rust options
can’t support hard links (no inodes)
Windows/WinFsp maybe more work to implement
Windows/Dokany Dokan-FUSE maybe unmaintained with some outstanding bugs
Linux / MacOS
fuse-mt - high level FUSE API wrapper for libfuse, as used by Syncer (github)
Windows
WinFsp - create user mode file systems on Windows, including an implementation of FUSE high level API (github,docs,Wiki)
“Finally note that this release contains the winfuse kernel driver, which exposes the FUSE protocol in the Windows kernel (via DeviceIoControl). It does not contain the wslfuse kernel driver, which will expose the FUSE protocol in WSL1 (via /dev/fuse)”
@danda I think it would do no harm to get developer feedback on any SAFE FS proposal early on especially from the core team (i.e. before we have the implementation fleshed out). The best way to involve core devs is probably on github via an issue or as a draft RFC, even if we end up throwing it away. But first obviously we need to get it to the point where you think it is sensible!
Still waiting on this, also in case we can make a provisional decision on which FUSE API to use:
This week I have made progress on the php tree-crdt code. In particular, I implemented the suggested execution optimization from the paper (lookup child_id in a hashmap). This sped up move operations but did not help listing child nodes, which is necessary for efficiently traversing the tree. So I added a parent → [child,…] index as well. With this in place, tree walks become quite fast. I also added lamport+actor timestamps, which actually work in a multi-process replicated situation… ie the impl doesn’t rely on any global knowledge crutch now. I also fixed an issue with dup ops entering the log if they have the same timestamp, added several test cases, etc. intend to make a little wiki writeup about it soon. The code is up on github if you’d like to check it out, and both the set-based (tree-set.php) and hashmap based (tree.php) versions can be run/compared.
The only major remaining work on the php code (today) is to implement basic log truncation (as per paper) and get some hands on experience with it. After that, I should be ready to start translating into rust next week.
I am not nearly at that point yet. There are still several unresolved issues in my mind, as well as lack of hands-on experience.
Just to name a few:
How exactly do we implement inode support?
How do we truncate logs, given that the complete set of replicas is not well known, and old replicas may come online at any time? ( today I am working on log truncation as specified in the paper, with known set of replicas.)
How exactly do we serialize metadata such as inode name, size, type, and so on? How can we do this most compactly/efficiently? Should we support extended/extensible attributes?
Ok, I have a couple thoughts to move us forward:
I would like to understand better some things that I haven’t had time yet to look into in depth. If you have time, that could be helpful:
a) how does a fuse filesystem come into being the first time? ie, how does init() work?
b) using the low-level API, how does a path get translated to an inode? eg, if I say ls /tmp/foo, when/how does /tmp/foo get translated to a u64? (which calls?)
c) when I create a file touch /tmp/bar, an inode record is created and a u64 to identify it. when/how is the u64 created?
The crdt paper does give some further hope about using inodes in section 3.6, but I don’t fully grok it yet, perhaps because I haven’t coded a filesystem from scratch before and have the above uncertainties regarding inodes.
Unix filesystems support hardlinks, which allow the same file inode to be referenced from multiple locations in a tree. Our tree data structure can easily be extended to support this: rather than placing file data directly in the leaf nodes of the tree, the leaf node must reference the file inode. Thus, references to the same file inode can appear in multiple leaf nodes of the tree. Symlinks are also easy to support, since they are just leaf nodes containing a path (not a reference to an inode).
So from that description, if leaf nodes only contain references to inode records, then I still don’t get: (a) where are the inode records are actually stored and (b) this doesn’t seem to resolve the u64 to UUID issue at all. @happybeing if you have any insights on this, let me know. Otherwise, I’m thinking to contact the paper authors after I understand a bit more about inode usage.
All the SAFE+network aspects and layers complicate things a lot. I’m thinking let’s start simple instead. crawl, walk, run. prove things out. We can embed the rust crdt tree type directly into the fuse stub that you build. It doesn’t need to do any communication with another peer/replica… just operating on its own. No other SAFE libs involved at all. This exercise will prove that the data type is workable (or not) for a local filesystem. We can identify/resolve the inode mapping issue. We can quickly have a functioning local fuse filesystem and begin to evaluate its performance characteristics as well as logging/caching, or any problem areas. Basically, if we can make this work well standalone, then that is a solid proof of concept. A networked version of it should then be doable and a logical extension, given the crdt properties.
Overall, looks a bit like the PHP filesystem api to me. Coming from a C background, I’ve always found those APIs very easy to use/remember as most are either thin wrappers around C functions or convenience functions that wrapper a few together, so that’s a plus in my book, though some may disagree. It’s probably best that we not make things too rust-specific, as there will be bindings for lots of other langs. My personal preference would be to keep func names the same as in C, rather than adding an _, ie getattr not get_attr.
Regarding the simplified APIs, I’m not really thinking that high level yet, but in general I’d suggest taking a look at what various languages do, eg PHP, python, rust, c#, etc and I think we can identify a common set of useful routines.
yes, I’d like to plugin the crdt-tree data type directly to test out a local-only filesystem, as I proposed in the preceding message. I’m hoping to have some prototype rust code working by end of next week, barring difficulties. Regarding file contents, it could be stored in metadata initially, or possibly in another mounted filesystem.
@danda just to say I’m working away both to improve my understanding of FUSE and filesystems, and to try and come up with some thoughts - maybe even answers - to the questions we have. I’ve covered a lot of ground and clarified some things by writing about filesystems and how to implement them on the FileTree with CDRT etc. I have some more to do and will then respond to your posts above.
Great to see you making progress with the Tree CDRT.
Ditto. I find it useful to write things down even if they get torn up so don’t take anything I come up with as the way I think it should be.
I have been mixing research about filesystems with thinking about implementation of SAFE FS for FUSE and marrying these with how I imagine the FileTree will need to work, and have made notes about possible implementations. But rather than force a lot of reading on anyone I’ll respond to your questions and drop bit in where relevant.
The billion dollar question. I’ve been thinking about this and have more investigation to do to establish how closely SAFE FS should try to emulate typical inode features, or whether for example, it can create and destroy them more like file handles. I don’t know if that’s a useful idea or not, or whether to place that in SAFE FS or FileTree. For example, it may help us by decoupling the needs of the FileTree/TreeCDRT node identifiers from those exposed by SAFE FS.
I’ve summarised my understanding of Unix/Linux filesystem, including inodes (here). There are some things I probably need to look into further, so I made that a Wiki topic for this which can be updated and discussed separately.
I’d also like to know how the idea of a u64 node identifier might work (or not) with a TreeCDRT if you have any thoughts about this. More on that in a bit.
I don’t know about the CDRT side of this but see you’ve made progress. I have a couple of thoughts of how to manage the truncation to keep it trim without losing functionality:
I think it’s desirable to be able to access the full log rather than ever lose it completely. I think each replica can do this, by moving any pruned entries to a Sequence owned by the replica so that the full log can be be reconstructed, while only a shorter one is needed for most operations. This will preserve the ability to roll any FileTree back through all its previous states, or to merge any two FileTree replicas regardless of age and pruning. Maybe this is a ‘for later’ feature, but we could make preserving pruned entries the priority and implement features to make use of this later.
it might be helpful for users to be able to control how and when the log is pruned to suit different use cases. This could either be set when creating the first replica, or perhaps something that can be modified at any time.
EDIT: Another thought as I think truncation has a second aspect. The first is trimming the log so it doesn’t become so large that performance degrades unacceptably.
The second is deciding to have a cut off, before which no replica is merged if it has unmerged entries proper to the cut off. Why might that be useful? I’m not sure, but it occurred to me while I was thinking about the inode problem, trying to avoid clashes for numbers allocated independently. I came up with the following solution which I think would require us to limit how far back mergers should be allowed to go. The downside of that is that all topics will have to sync to stay ahead of the cut-off, or face their changes being blocked. That is recoverable though through a user managed re-sync, and I think for most use cases unlikely to be an issue, so how might having a cut off help as described in: Allocating inode numbers using pre-allocated blocks
I’ve not thought about this so idiot mode activated… The FileTree will be responsible for this because it will be a part of the CDRT operations, and so it will need to keep track of the metadata for each node, serialise it and retrieve it etc.
As for how to serialise it I’m not sure. Does it make sense to have a column in the log for each attribute or to have a single column for all metadata? In the latter case perhaps the metadata is serialised to a Sequence, in the former to the log itself but using run-length-encoding to avoid having to store values which rarely change, or maybe a bit of both?
Assuming this is just more metadata that’s something we could bolt on later so not an urgent question, but in general I’d say we try to implement everything we can in the long term in ways that don’t hurt performance until they are made use of by an application.
The init() operation is used to inform us about the characteristics and parameters of the FUSE kernel, and allows us to tweak some things if we want. Nothing exciting, but will need attention at some point (see docs).
You may be more interested in how we start up when a user tries to create or mount a SAFE FS filesystem. I expect we’ll have an API for creating a new FileTree object and from that object gain access to a SAFE FS API which SAFE FUSE can use to provide the filesystem operations on the FileTree.
So for example a safe-fuse CLI will be invoked with parameters telling it to either create a brand new filesystem (i.e. create an empty FileTree object for it), or an existing replica (i.e. fetch an existing FileTree from the network), and mount it at a given path. Once safe-fuse has a FileTree it obtains a SAFE FS API from it, then passes its FUSE operations to libfuse along with the requested mount point.
(Not necessarily in that order! As in, it might be better to create the mount first but block any operations until we have obtained the FileTree rather than keep the user waiting for that before failing the operation because they gave an invalid mount point.)
Another ‘I think’: from the application side you must always start with a path (you can’t just have an inode number and begin using that, is my understanding - except perhaps for the ‘root’). From the path you can obtain an inode which identifies the thing for subsequent operations on the same thing (typically a file or directory). This is hidden from view when using high-level FUSE. With low-level FUSE, the you call lookup() to get an inode number, which you then use for subsequent operations on the object it represents (e.g. a file or directory). The lookup() increments a hard-link count for the inode, so your process now effectively has a hard-link to the object, which is released when you call forget() which decrements the hard-link count. I see these hard-links as different (ephemeral) from hard-links from a directory entry to a file (enduring), and may be handled differently in our implementation. For example, if a process crashes before calling forget() it is probably better for the ‘link’ to die with it than to leave the inode in a state where its hard-link count will not reach zero when all its other hard-links have been removed.
Part of my to-do list is to look into this: how important it is that SAFE FS inodes correspond to typical filesystem inodes as it may be useful to deviate from this if it makes life easier for the FileTree/TreeCDRT implementation and its interface to SAFE FS.
I imagine it typical filesystem initialises an empty fixed sized table of inode references which has entries filled in or erased as file system objects are created and destroyed.
In terms of the APIs, the filesystem will call our FUSE API with a path in order to create an inode. We respond with the inode number, and it will use that for subsequent operations. So we would probably create an entry in the tree at this point, allocate it a u64 and respond with that.
For example:
OS-FUSE obtains the inode number for an entry in the root (‘/’) using an inode number of 1, so to get the inode for ‘/tmp’ it will call lookup(req_handle, 1, 'tmp')
If ‘/tmp’ exists we respond with a value, say I’ll call tmp_inode (which might be 2).
OS-FUSE then calls our create(req, tmp_inode, 'bar') to create the file entry.
We find the FileTree node which has an id of tmp_inode, create a child entry with name ‘bar’ and allocate an inode number for the entry (bar_inode) and initialise the metadata for the entry (e.g. creation time).
We respond with the inode number (bar_inode) of the new entry.
If that’s not complicated enough there’s a bit more to it than this so it is going to need a lot of reading and careful thought to ensure a clean, robust design.
Just read this part (possibly again), and it is what I had concluded after lots of thinking about how to implement hard-links. TL;DR: it works so long as we only need links to leaf nodes. This is ok IMO because only MacOS allows hard-links to directories.
Re a): Where the inode has only one reference, i.e. for directories, symlinks and files which don’t have extra hard-links, we could use the FileTree/TreeCDRT node to hold the metadata of the inode. In this case a file is just metadata, including an xor address (similar to a FilesContainer entry). So for most cases we just need a way to map between inode number and FileTree/TreeCDRT node in order to access the data of an inode.
In the case of a hard linked file, we will need a separate object to hold the inode data which can be referenced by every entry which hard-links to it from a directory. I have a scheme in mind where we store that in a Sequence but I won’t go into details here. If this passes scrutiny, the nice part is that we can start without support for hard-links and add it later.
Re b): I need a recap of this. Can you point me at anything or write a post explaining how the UUID is used, how the CDRT operates in this area? My head is filled with FUSE and I need a refresh of the CDRT side (or maybe a summary doc of what you envisage would help).
I agree with building in that way, and also find it useful to set out what I’m aiming at long term even if we end up somewhere else! I can also try to see the stepping stones we can use along that incremental path (e.g. the point about being able to add hard links later).
@happybeing good stuff. I’m headed out the door now. Will give it some thought and get back to you later.
re UUID, the tree is logically composed of a set of triples: (parent_id, metadata, child_id). There is a requirement that the parent_id and child_id must be globally unique, such that any actor (replica) can create one and it will not conflict with an ID created by another actor.
The metadata can contain things like name, size, etc. So we could stick a u64 in there, perhaps generated by some kind of hash of the uuid (simplest, though collisions possible). Or possibly it could be implemented as a g_counter, which is a crdt grow-only counter type. We probably would need to somehow index name and ino fields of the metadata for fast lookup in large-directory situations.
Ok, I’ve been thinking more about how to implement hard-links, and I have an idea.
first, the issue is that:
rather than placing file data directly in the leaf nodes of the tree, the leaf node must reference the file inode. Thus references to the same file inode can appear in multiple leaf nodes of the tree
Now my original thinking was that:
each tree node is an inode entry.
our file content is stored as an ImmutableData and referenced by XorName from leaf nodes.
Given 1 and 2, multiple leaf nodes may point at the same XorName, which effectively implements hard-links. (for files ony)
So, the challenge then is how to achieve the indirection in the second example, using our crdt-tree.
My first thought was that we could store the inode_entry data in an immutable object, but this is pretty terrible because its basically useless for working offline, would have super slow lookups, the XorName is based on changing metadata, etc, etc. I hate it.
So, the question becomes: how do we store the inode_entry in the crdt-tree itself? Well, I think there is a way.
The paper discusses that the data type supports multiple root nodes, not just one. The authors call this a forest, and suggest a method to implement deletions by creating a trash node as a sibling to filesystem root, and each delete (final unlink) is implemented as a move to the trash. I recently implemented a test case for this, and the output visually demonstrates:
$ php tree.php test_move_to_trash
Initial tree
- forest
- root
- home
- bob
- project
- a
- a
- b
- b
- a
- b
- trash
After project moved to trash (deleted) on both replicas
- forest
- root
- home
- bob
- trash
- project
- a
- a
- b
- b
- a
- b
Delete op is now causally stable, so we can empty trash:
- forest
- root
- home
- bob
- trash
So my idea now is that we can create another sibling of root called inodes and we store each inode_entry as a child of inodes, in the tree-node’s metadata, eg:
Hopefully that is clear enough for others to follow my train of thought. @happybeing please let me know what you think.
I think this works. At least I see a clear enough path that I should be able to try out a test case with the prototype, as I did for moves to trash and emptying trash.