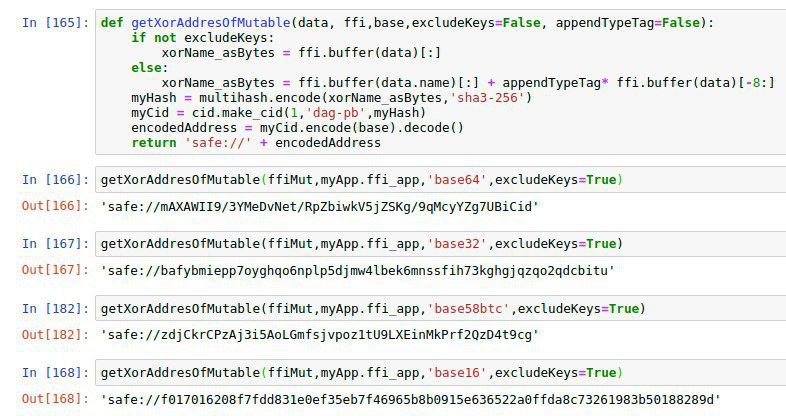
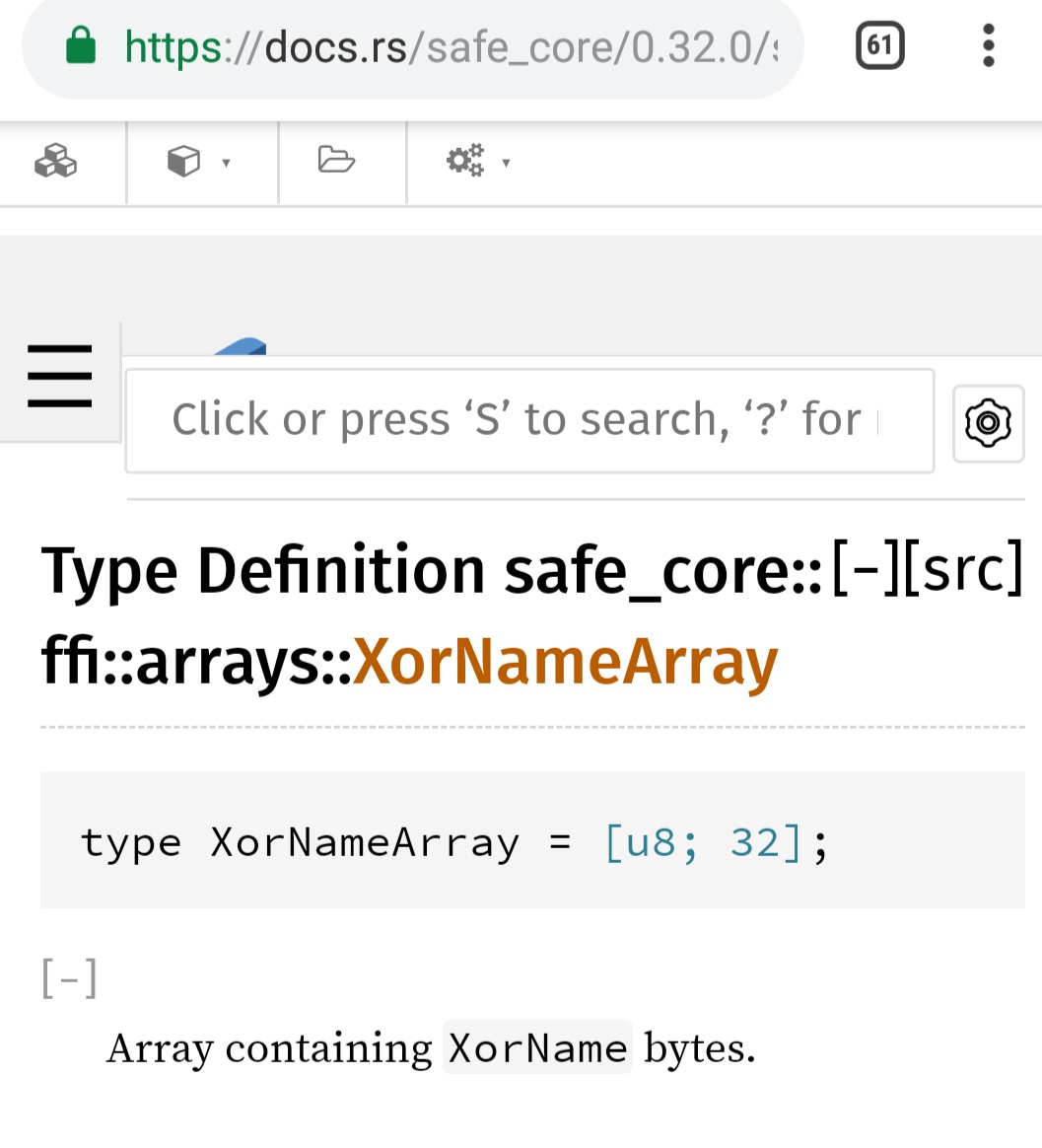
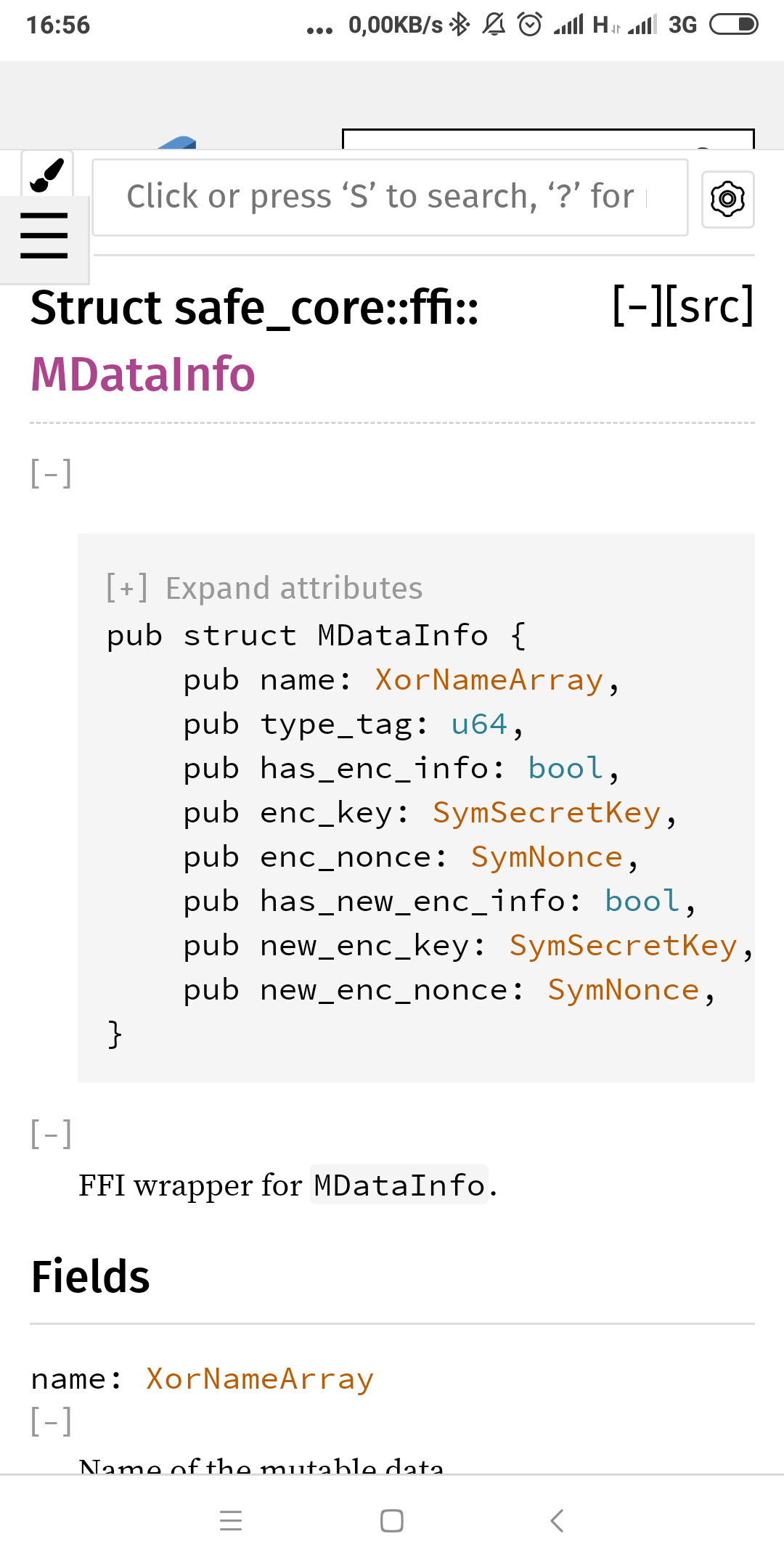
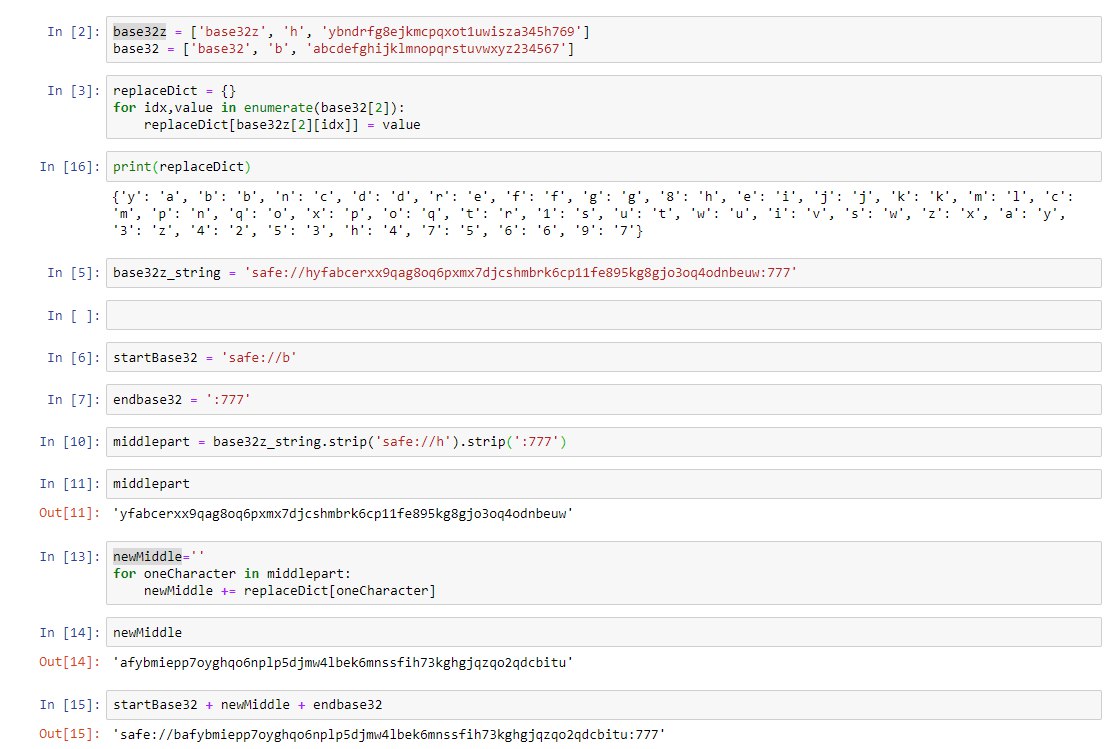
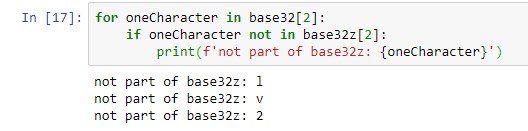
Okay – playing with immutables now …
and here again there is the question how xor-links are supposed to work for me
i uploaded a jpg to this xor-name (hex)
30a3fcb0130310087d0890da0143a594b40dd96b7536de15892d78ee264a6813
and the same file as png to this xor-name (hex)
2d50dd18645fe99a98b89271b44d10c612ca2cb168eba51e4ea3ce7909689583
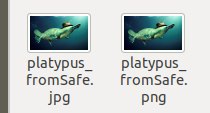
i know that it‘s really there because i downloaded it on a different pc and both downloads succeeded without error
since the prefix you used for your png link at safe://hygjdkftyx3k7kr51q9mxapy418zk3stdsss8suyqcim3b56jcten8d4j9emo is not in the python implementation of multicodec i „added it manually“ to my local version of it (just smuggled it into the source code)
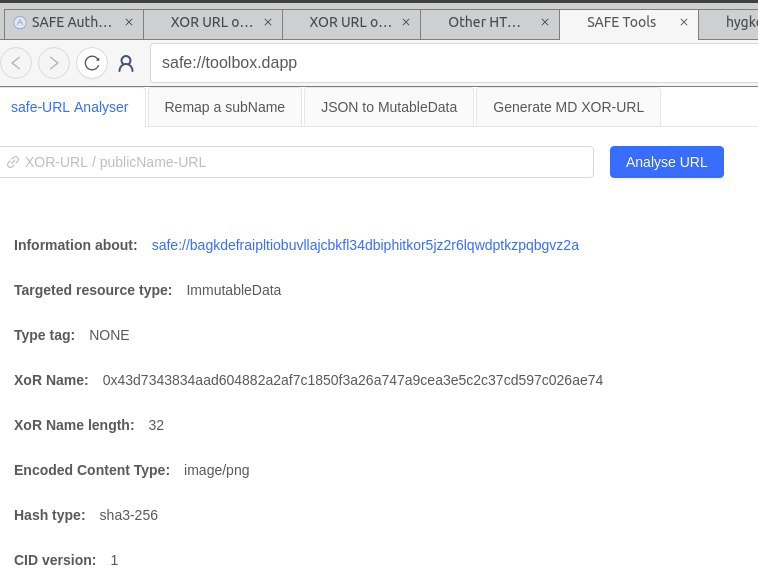
then i used the safe://toolbox.dapp to analyse the picture link you provided to extract the xor-name – i can download the lamp and get the data …

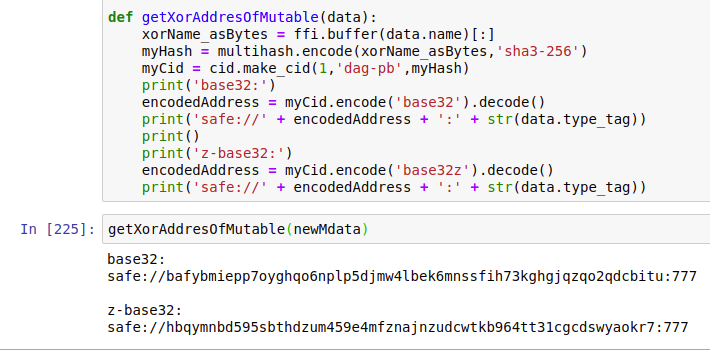
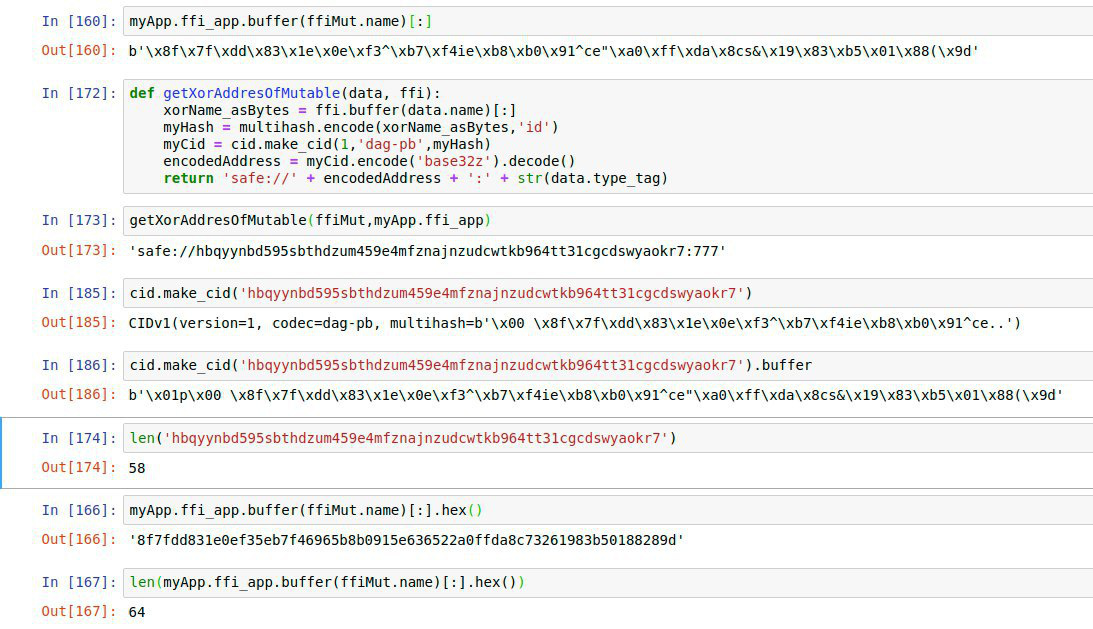
when i convert it to a cid i get as base32:
safe://bagkdefraipltiobuvllajcbkfl34dbiphitkor5jz2r6lqwdptkzpqbgvz2a
which seems to be fine (page loads – toolbox analyses)
for base32z then suddenly i only get ‚roughly‘ what your link is (pay attention to the 2 additional y‘s) and safe://hygkdrftyexmueqbwimmyjnbkfm5hdbex8eukqt7j34t6mosdxuk3xobgi34y then analyses fine again with the toolbox + loads the picture (so it‘s definitely not ‚just base32z encoded‘ but somehow there are additional characters that were not there before [and imo are not supposed to be there – since it‘s 2 additional characters that obviously don‘t contain any information … otherwise the base32 encoded data wouldn‘t analyze and work…])
if i try the same with my uploaded png i get:
safe://bagkdefrafvin2gdel7uzvgfysjy3itiqyyjmulfrndv2khsouphhscliswbq
which doesn‘t let me view the png in the browser and doesn‘t analyse with the toolbox,
base32z
‘safe://hgkdrftyfiep4gdrm9w3igfa1ja5eueoaajcwmftpdi4k81qwx881nme1sbo’
fails too – and with the 2 additional y‘s (as in the example link)
‘safe://hygkdrftyexmueqbwimmyjnbkfm5hdbex8eukqt7j34t6mosdxuk3xobgi34y’
it fails as well …
so what am i doing wrong with my png?
If i messed up something how is the precise specification of the xor-url of an immutable? why are there those 2 additional y’s? ( ) and why don’t we just append the mime type to the bytes and encode it just the same way we did before …?
) and why don’t we just append the mime type to the bytes and encode it just the same way we did before …?
As it is now for me in python - I need to manually patch the multicodecs implementation to have the required mime types (not sure how standardised that is - and how widely used… The last update of the hash constants on github for python was 2015… where do those codec-numbers come from anyway? I didn’t see them in the iana link from the github issue and the used codec for the png is not the in the issue mentioned x1910 but x1914…? May we run into collisions with the definitions suddenly? ) then I can generate a link (which only works in some cases as it seems)…
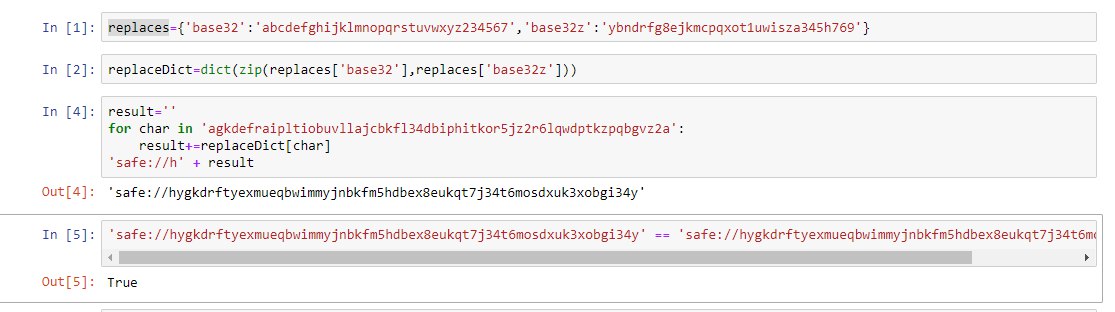
Ps: oh sorry! My mistake with the y! I think I made a copy&paste error with the base32z declaration dict… On second view the lengths of the links looked fishy 

Then your base32z link is perfect - it’s just that I fail with generating the right link to my uploaded png



 well that was very helpful now =)
well that was very helpful now =) … (i’ll read something about it later on … thanks for clarification =)
… (i’ll read something about it later on … thanks for clarification =)