@bzee, I think this was just trying to mean that if the resolver supports to fetch and decrypt MD entries it may need to try first to decrypt them and if that fails then simply assume that entry is unencrypted, in priv MDs entries can be both encrypted but some unencrypted. I’ll be looking at applying some of the corrections made above by @mav so I’ll try to also enhance this paragraph as this bit is definitely not clear at all.
I think the confusion here has to do with the fact that the RFC is talking not just about the XOR-URL spec being proposed, but also how we can/want to support it with our resolver, i.e. our webFetch and fetch browser embedded functions.
E.g., if you are fetching a WebID with a fragment, I thought it would be desirable to have the fetch/webFetch to already take care of it and return the corresponding graph (in cases you have more than one foaf:Person graph in the same WebID), but it’s also true an app may not want that and would prefer to obtain the complete WebID profile doc for it to process the fragment (or not ![]() ). This can probably be an option which can be passed in when invoking the resolver stating if the fragment shall be processed by the resolver, or as you suggested, simply have the resolver to not support fragment inspection/resolution.
). This can probably be an option which can be passed in when invoking the resolver stating if the fragment shall be processed by the resolver, or as you suggested, simply have the resolver to not support fragment inspection/resolution.
When looking at how to encode the type tag I was having the same type of thoughts and point of view as @bzee, I don’t think MD urls are literally querying a specific type and/or version of a MD in the sense that querying is supposed to be something targetting the client app or website, and nothing to do with the resolver or how to route the request, just like the fragment. So we thought that since the type tag is used by the vault to retrieve the service/content (as bzee says you cannot do it without a type tag), it fits quite well trying to make an analogy with port numbers.
I think along the same lines for the version, this is not defined yet how it will work, so we don’t know if different versions of the “same” content would be store/hold by the same section/group, I presume it all depends how this will be implemented. And even if they are in the same section/group, providing the version is/will still be part of the routing/locating mechanism rather than something dealt by the client app.
Now, I have recently started to think about the need of a type tag number, simply considering not having type tags at all to route and locate any type of content. From a user’s perspective, why do I need a “number” to locate a content on a network which holds immutable versionable data, for which I already have a hash of the content I’m looking for? AFAIK, the idea behind the type tag was to be able to have the network (vaults) to act upon data in specific ways for predefined type tags, e.g. safecoin is typetag X so mutations/requests for such MDs can be treated in a special way. But what if we can do that in some other way and remove the type tag altogether? wouldn’t that be a much cleaner CAS and URLs?
(Note I have no clear understanding yet if it’s possible to get rid of type tags but throwing it for consideration as well)… thinking out loud, what if some bits of the XOR address are actually the type tag, and what if we even expand the XOR name address space if we want to have 256 bits for it and add some more bits which are used for type tag? @ustulation / @nbaksalyar does this sounds too crazy/wrong?
I would be more inclined to this option rather than any of the other where querystring or fragment is used for any of the type tag or versioning. I’m also thinking of the suggestion from @hunterlester Cannot fetch content with a XOR-URL which typeTag is greater than 65535 · Issue #429 · maidsafe/sn_browser · GitHub, what if we propose an addition to the multiformat protocol where you can append some custom data and which we use to encode the type tag number. I’ll have to think about this more thoroughly though.



 well that was very helpful now =)
well that was very helpful now =) … (i’ll read something about it later on … thanks for clarification =)
… (i’ll read something about it later on … thanks for clarification =)
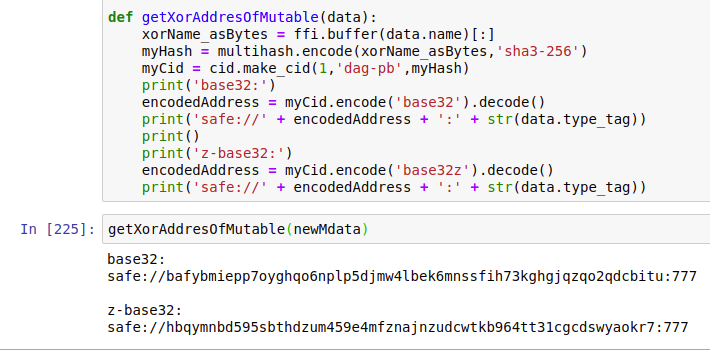




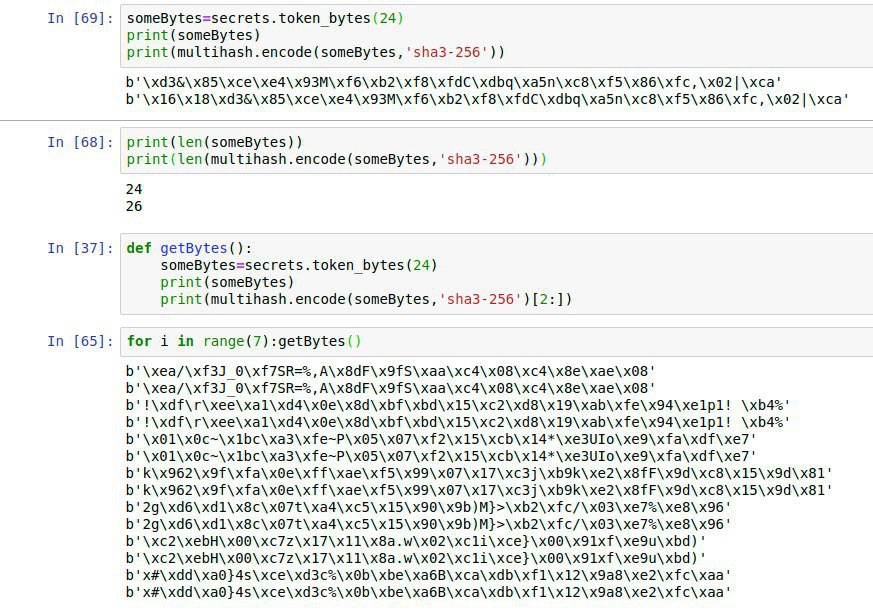
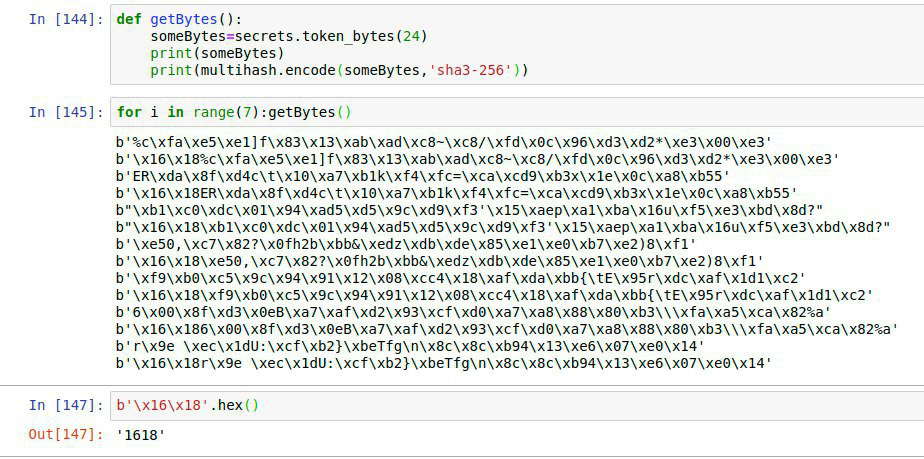
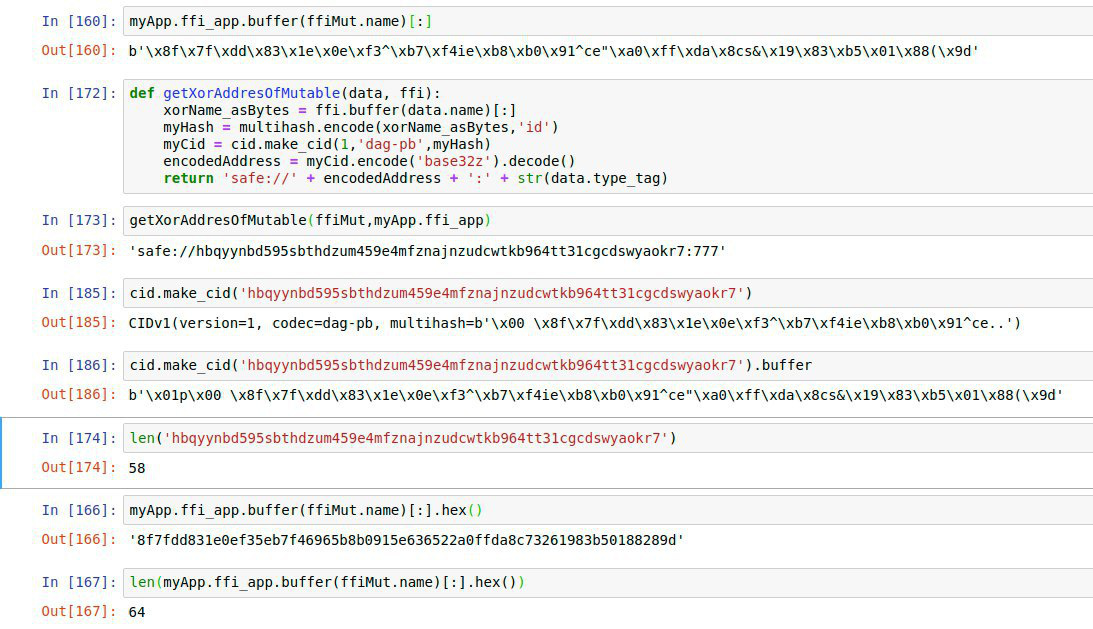

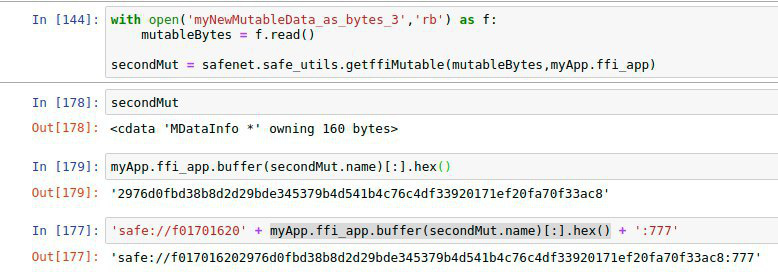
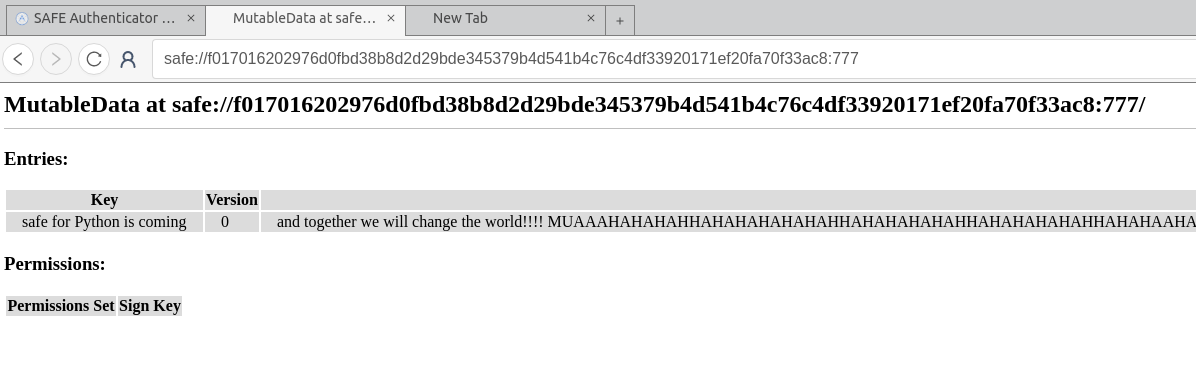
 ] he can just hex the xor-name, put e.g. ‘safe://f01701620’ (description: sha3-encoded + first patch-bytes because the xor-address is shorter than the checksum, bytes then hex-encoded) in front of it and have a working link to the newly generated mutable:
] he can just hex the xor-name, put e.g. ‘safe://f01701620’ (description: sha3-encoded + first patch-bytes because the xor-address is shorter than the checksum, bytes then hex-encoded) in front of it and have a working link to the newly generated mutable: