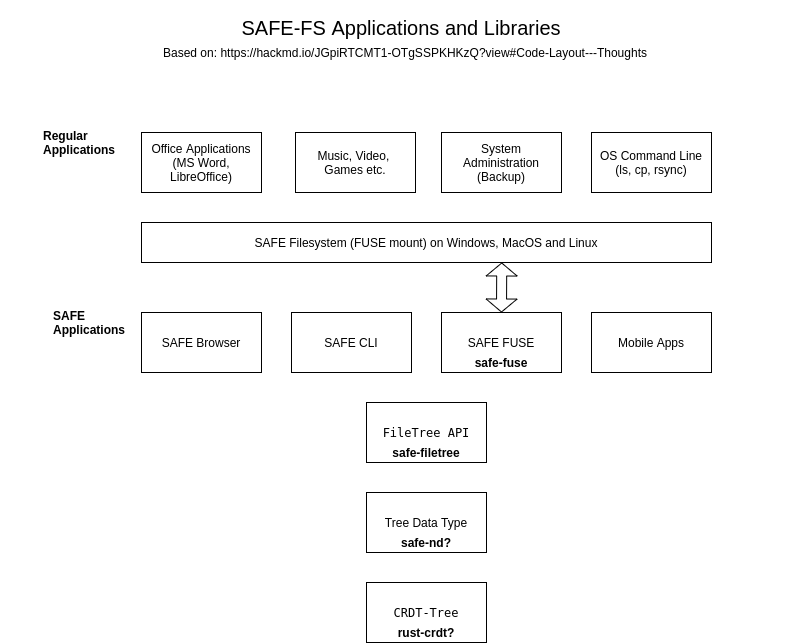
@happybeing’s notes on the following excellent talk:
CRDTs: The Hard Parts — Martin Kleppmann’s talks (link)
[Video see 35:30]
by Martin Kleppmann very clear Cambridge Academic.
The point of this talk is to show how to implement CRDTs so they behave well, which is the hard part. [10:20]
Topics:
- Interleaving anomalies in text editing
- Moving (re-ordering) list items
- Moving sub-trees of a tree
- Reducing metadata overhead of CRDTs
Intro to Operational Transformation and CRDTs
A very good intro to updating shared data by Operational Transformation (Google Docs pre-2006 tech) and Conflict-free Replicated Data Types (post 2006 tech)
[03:50] Operational Transformation (Google Docs pre-2006 tech)
[06:40] OT relies on assumption and requirement: all communication must go via a central server
[08:00] Conflict-free Replicated Data Types (post 2006 tech)
Does not require a central server.
Convergence is guaranteed if any two nodes have seen the same set of operations (even if in a different order), they will be in the same state.
But the final state may not be good "CRDTs are really easy to implement badly" -> its actually a hard problem to get CRDTs to satisfy user expectations.
The point of this talk is to show how to implement CRDTs so they behave well, which is the hard part.
Interleaving anomalies in text editing
[10:38]
(Published at PaPoC 2019)
Every character has a unique id, which remains the same forever. Ids are chosen to preserve the ordering within the document. Document can be implemented as a set of tuples (which include an element for the source node).
[16:00] Jumbles of letters can arise when nodes choose the same number for a given position.
[17:40] Table of six CRDT algorithms and how well they do this. Two avoid this issue very well: Treedoc and WOOT, but these are very inefficient…
[19:30] RGA has a lesser interleaving problem, but he has solved this and published this improvement to RGA
Moving (re-ordering) list items
[25:50] All the preceding algorithms support insert and delete, but not move. If you implement move with insert and delete, concurrent moves of the same item result in duplication.
[29:30] Can be solved with existing ‘last writer wins register’ CRDT technique. All CRDTs have an identifier that can be used to implement this.
[32:38] gets more difficult if you want to move more than one item at a time
[34:30] this is an unsolved problem!
Moving sub-trees of a tree
[35:30] Concurrent moves of the same node is a similar problem to moving elements in lists
Desirable outcome (for trees) is to use ‘last writer wins’ (LWW) behaviour to select one or other of the moves as the deterministic result.
[38:22] **Trees are harder than lists, have additional complications. ** Example, moving a-b to b (moved node is an ancestor of the destination).
Our CRDT could disallow this because it breaks the tree (making it a graph), but unfortunately we have the problem of concurrent changes.
[39:46] Best outcome is again to have an LWW choose which of the moves happens and that becomes the deterministic result (effectively choosing one or the other move, and ignoring the other).
Testing on Google drive, it hasn’t solved this!
[42:55] Solution is to give each operation a time stamp
Each node has its own series of operations. To merge two overlapping sequences, apply the changes from the other in time order and if necessary, undo your own operations so that the next operation being merged is applied to the one just preceding it. Operations can then all be applied in time order.
[47:xx] Performance good enough for local users moving stuff around their file system (e.g. 600 moves per second), but not so good for big data.
Key slide
[48:00] How it works!
struct MoveOp {
TimeStamp time; * Globally unique (e.g. Lamport timestamp. See also Difference between Lamport timestamps and Vector clocks on stackexchange.)
NodeId parent; // Destination of move
Metadata meta; // e.g. filename within parent directory
NodeId child; // subtree being moved
}
When performing the move we create a log entry which is a copy of the MoveOp plus two additional fields:
Option oldParent; // empty if previously not in the tree
Option oldMeta; // empty if previously not in the tree
Key slide
[50:14] Tree is a set of triples (parent, meta, child)
[50:54 ] Formal definition of the move operation
[52:18] We proved several theorems about this:
- every tree node has a unique parent
- the tree contains no cycles
- it’s a CRDT
Note: using NodeId allows us to ‘steal’ the node from whereever it currently is, so we don’t care where it is when we take it.
☐ Does this conflict with ‘path based’ cf. @danda 's quandary?
Reducing metadata overhead of CRDTs
[53:13] Making CRDTs more efficient - can easily have 100 bytes of metadata for one byte of the document!
Their work on making CRDTs is being done in their automerge CRDT (github: javascript version, Rust version)
“A JSON-like data structure (a CRDT) that can be modified concurrently by different users, and merged again automatically.”
Results table for different degrees of pruning using their solution, and without it.
[1:01:20] How this works…
- store all insertion and delete operations
- each op has a lamport timestamp as its id
- each op references its predecessor
- store ops in document order
[1:02:25] Figure: Columnar encoding - each row is one operation. Last column records the operation which deleted this character (which might have more than one value if it was deleted by more than one user).
[1:04:13] Encode the table using some simple tricks…
key point:
[1:08:00] This demonstrates that tombestones are not that significant (enables CRDT merging with any other CRDT?) in terms of size, compared to using an efficient binary encoding format such as the one presented here.
References:
[1:09:45] Refs for each of the CRDT algorithms mentioned: Logoot, LSEQ, RGA, Treedoc, WOOT, A-strong
[1:09:55] Refs for publications Martin has contributed to:
- Interleaving anomaly (2019)
- Proof of no interleaving in RGA (2018)
- Moving list items (2020)
- Move operation in CRDT trees (Preprint)
- Reducing metadata overhead (2019) https://github.com/automerge/automerge-perf/blob/master/columnar/README.md
- Local-first software (2019) (online):
In this article we propose “local-first software”: a set of principles for software that enables both collaboration and ownership for users. Local-first ideals include the ability to work offline and collaborate across multiple devices, while also improving the security, privacy, long-term preservation, and user control of data.
[end] Useful links: https://crdt.tech/, https://twitter.com/martinkl, mk428@cl.cam.ac.uk